
ChatGPT는 20B 크기의 모델?!
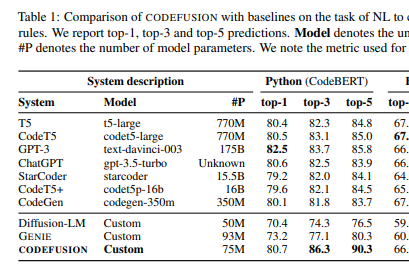
Microsoft Research에서 EMNLP 2023에 제출한 논문인 "CodeFusion: A Pre-trained Diffusion Model for Code Generation"에서 ChatGPT(gpt-3.5-turbo)의 파라메터 개수가 20B로 공개되었습니다.
- T5 (t5-large): 770M
- CodeT5 (codet5-large): 770M
- GPT3 (text-davinci-003): 175B
- ChatGPT (gpt-turbo-3.5): 20B

여론이 시끄럽자 후다닥 삭제한....
"There are some errors in the paper and we need to retract it"
과연 20B가 맞을지? 정정할지..??!
물론 반대의견도 존재합니다 https://www.reddit.com/r/LocalLLaMA/comments/17lvquz/clearing_up_confusion_gpt_35turbo_may_not_be_20b/
GPT4는 25000개로 약 100일동안 학습..??!!
https://towardsdatascience.com/the-carbon-footprint-of-gpt-4-d6c676eb21ae
후... 대단한 사람들....
The creation of GPT-3 was a marvelous feat of engineering. The training was done on 1024 GPUs, took 34 days, and cost $4.6M in compute alone [1]. Training a 100T parameter model on the same data, using 10000 GPUs, would take 53 Years. To avoid overfitting such a huge model the dataset would also need to be much(!)
그리고..
According to unverified information leaks, GPT-4 was trained on about 25,000 Nvidia A100 GPUs for 90–100 days [2]. ... 90–100 days to train GPT-4.
..??!!!
KISTI, 과학 데이터 특화 LLM '고니 13b' 개발
https://www.aitimes.com/news/articleView.html?idxno=155990
KISTI, 과학 데이터 특화 LLM '고니 13b' 개발 - AI타임스
한국과학기술정보연구원(KISTI, 원장 김재수)은 대형언어모델(LLM) \'고니(KONI, KISTI Open Natural Intelligence) 13b\'를 개발했다고 20일 밝혔다.과학기술데이터에 특화되고, 출연연이나 공공기관에서 활용
www.aitimes.com
https://www.aitimes.com/news/articleView.html?idxno=153552
미디어젠, KISTI와 AI 기반 ‘신약 후보물질 정보 생성장치’ 공동 특허 등록 - AI타임스
미디어젠(대표 고훈)은 한국과학기술정보연구원(KISTI, 원장 김재수)과 인공지능(AI)과 계산과학을 활용한 AI 기반의 신약 후보 물질 발굴에 관한 특허를 공동 취득했다고 11일 밝혔다.이번 공동 특
www.aitimes.com
보안에 민감한 정출연에서 활용하는 AI
H2O LLM Studio
https://h2o.ai/platform/ai-cloud/make/llm-studio/
H2O LLM Studio
With LLM Studio, you can:
h2o.ai
최첨단 대규모 언어 모델(LLM)을 미세 조정할 수 있도록 설계된 프레임워크 및 코드가 필요 없는 GUI
RLHF(인간 피드백 기반 강화학습)의 원리
카카오뱅크의 금융특화 언어모델 KF-DeBERTa
Max length 512 같은 모델들은 긴 input을 받을 수가 없으므로 정제해서 자르거나, stride를 주면서 하나의 input을 쪼개서 모델에 여러번 태우는 방식을 사용해야한다.
이 max length은 positional encoding 때문에 생기는데, 토큰의 절대적 위치 기준으로 위치 정보를 인코딩하기 때문에 위치정보 1~512가 인코딩된 모델의 입장에서 513이 들어오게 되면, 한 번도 보지 못한 정보이기 때문에 모델이 제대로 동작할 수 없게 된다.
DeBERTa의 경우, 요즘 디코더에 많이 쓰이는 RoPE처럼 토큰위치를 관련정보에 기반해서 (i토큰과 j토큰 사이의 거리) 매 레이어마다 넣어주기 때문에 이론상 context length가 엄청 길어질 수 있다.
애플표 생성AI, 오는 6월 WWDC서 발표
https://zdnet.co.kr/view/?no=20240108102109
"애플표 생성AI, 오는 6월 WWDC서 발표"
생성 인공지능(AI) 기술 분야에서 경쟁사에 뒤쳐져 있다는 평가를 받고 있는 애플이 오는 6월 개최되는 WWDC2024 행사에서 그 동안의 개발 내용을 공개할 예정이라고 블...
zdnet.co.kr
생성 인공지능(AI) 기술 분야에서 경쟁사에 뒤쳐져 있다는 평가를 받고 있는 애플이 오는 6월 개최되는 WWDC2024 행사에서 그 동안의 개발 내용을 공개할 예정이라고 블룸버그통신이 7일(현지시간) 보도했다.
애플 블로그
https://machinelearning.apple.com/research/vision-transformers
기대가 되는군요.. +_+ 시리에다가 생성AI를 활용하지 않을까 싶은데!
애플이 상대적으로 좀 조용하긴 했죠
ChatGPT-Scispace 등장
https://chat.openai.com/g/g-NgAcklHd8-scispace
ChatGPT - SciSpace
Do hours worth of research in minutes. Instantly access 200M+ papers, analyze papers at lightning speed, and effortlessly draft content with accurate citations.
chat.openai.com
유료구독자만 사용가능한 것으로 보인다
효율적인 LLM 학습 전략
효율적인 LLM 학습 전략
효율적인 LLM 학습 전략
momozzing.github.io
1. 모델 양자화
2. 모델 일부 파라미터만 학습
Stability.ai의 LLM 모델 발표: Stable Code 3B
https://stability.ai/news/stable-code-2024-llm-code-completion-release
Stable Code 3B: Coding on the Edge — Stability AI
Stable Code, an upgrade from Stable Code Alpha 3B, specializes in code completion and outperforms predecessors in efficiency and multi-language support. It is compatible with standard laptops, including non-GPU models, and features capabilities like FIM an
stability.ai
Stable Code 3B는 30억 개의 파라미터를 가진 대규모 언어 모델(LLM)로, 2.5배 더 큰 CodeLLaMA 7b와 같은 모델과 동등한 수준의 정확하고 빠른 코드 완성을 지원합니다.
맥북 에어와 같은 일반 노트북에서 GPU 없이도 오프라인으로 작동합니다.
Upstage와 함께 하는 글로벌 OpenLLM
리더보드 1위 모델 리뷰 & LLM 모델 Fine-tuning
https://fastcampus.co.kr/data_online_llmpaper
Upstage와 함께 하는 글로벌 OpenLLM 리더보드 1위 모델 리뷰 & LLM 모델 Fine-tuning | 패스트캠퍼스
LLM 리더보드 세계 1위의 시각으로 배우는 논문 선별 노하우과 모델 파이프라인 구축 방법!
fastcampus.co.kr
LLM 강의가 은근 귀한데 오랜만에 업스테이지에서 들을만한 강의가 나온 것 같다.
AWS GPU Cost Calculator
https://pattersonconsultingtn.com/content/aws_cloud_gpu_calculator_v1.html
AWS GPU Cost Calculator
This is a calculator to give you a rough estimate for what your team's GPU costs on AWS for Deep Learning based on their usage patterns.
pattersonconsultingtn.com
이런것도 있다 ㅋㅅㅋ 재밌군
Mixtral of Experts
스타트업 회사인 Mistral AI 에서 지난 8일에 Mixtral 8x7B 모델을 오픈소스로 출시하였습니다. 지난 9월에 출시한 Mistral 7B 모델 기반으로 현존 언어 생성 분야에서 최고 성능인 GPT-4에서 채택중인 “MoE” 방식을 사용하여 파라미터 수가 더 많은 Llama 2 70B, GPT3.5 모델보다 자연어 벤치마크 성능이 뛰어나고, 추론 속도도 빠르다고 설명하고 있습니다.
논문: https://arxiv.org/abs/2401.04088
뉴스: https://mistral.ai/news/mixtral-of-experts/
블로그: https://huggingface.co/blog/mixtral
설명영상: https://www.youtube.com/watch?v=kueN7DV6Vqs
'TIL(Today I Learned)' 카테고리의 다른 글
| [TIL] 최근의 IT AI 이슈 정리_금융LLM, 딥페이크 보호, 일론머스크 Grok1.5 (0) | 2024.04.05 |
|---|---|
| TIL 240201- GPT5, MambaByte, ICLR2024 (1) | 2024.02.01 |
| TIL 231207 - 구글 Deepmind, Gemini 발표하다 (0) | 2023.12.07 |
| TIL 231124 - 잘 명령하기: 프롬프트 엔지니어링, LoRA: 비용 줄이기 (0) | 2023.11.24 |
| TIL 231123 OpenAI 세상 구경하기 (1) | 2023.11.23 |