
Describing Syntax: Terminology
Sentence
Language: set of sentences
Lexeme: syntactic unit(의미적요소)의 최소단위
Token: Lexeme의 카테고리_ 종류: 식별자, 연산자, 수치 리터럴, 특수어
Syntax: (구조, 문법): expressions, statements, and program units 어떻게 표현?
Semantics: (의미): expressions, statements, and program units 적합한가?
Syntax를 표현하는 방법
CFG(Context-Free Grammar)
Chomsky위계의 Class2로
다음과 같은 형식을 따릅니다.
A->x
A: nonterminal symbol (LHS)
x: a string that is composed of terminal or nonterminal symbol(RHS)
문법 G=(V, ∑, S, P) 에서 모든 생성규칙(production rule) 이 A->x 의 형태를 가지면
G를 context-free-grammar (CFG)라고 정의합니다.
V: 문법에서 사용되는 기호들
∑(T): Terminal Symbols
S: Start Symbol (nonterminal symbol)
P: Production or Rule 규칙
BNF(Backus-Naur Form)
BNF는 다른 언어를 표현하기 위한 메타언어입니다. CFG의 한갈래입니다.
<LHS> -> <RHS>
ex) 대입문 형식 <assign> -> <var>=<expression>
<assign>은 LHS, <>기호는 해당구문구조에 대한 추상화를 의미합니다.
RHS인 <var>=<expression>은 total=subtotal1+subtotal2로 생성될 수 있는 문장입니다.
<var>이 total, <expression>이 subtotal1+subtotal2. 이는 terminal symbol입니다.
Deriviation(유도)
BNF나 CFG의 규칙에 따라 주어진 문장을 만들어 나가는 것을 말합니다.
그렇게 만들어진 최종 구문을 Sentence라고 하고 이는 all terminal symbols입니다.
언어가 만들 수 있는 Sentence의 집합을 Language라고 합니다.
언어의 문장들을 시작기호(start symbol)라 불리는 문법의 특정 nonterminal부터 시작되는 일련의 규칙 적용을 통해 생성하는 것입니다.
예시문법을 들겠습니다.
<program>->begin<stmt_list>end
<stmt_list>-><stmt>
| <stmt> ; <stmt_list>
<stmt> -> <var> = <expression>
<var> -> A | B | C
<expression> -> <var> + <var>
| <var> - <var>
| <var>
유도과정입니다.
<program>
->begin <stmt> ; <stmt_list> end
->begin <var>=<expression>;<stmt_list> end
->begin A=<expression> ; <stmt_list> end
->begin A=<var>+<var> ; <stmt_list> end
->begin A=B+<var> ; <stmt_list> end
->begin A=B+C ; <stmt_list> end
->begin A=B+C ; <stmt> end
->begin A=B+C ; <var>=<expression> end
->begin A=B+C ; B=<expression> end
->begin A=B+C ; B=<var> end
->begin A=B+C ; B = C end
이는 Leftmost derivation으로 맨 왼쪽의 nonterminal 부터 순서대로 유도를 진행한 것입니다.
유도 순서는 생성되는 언어에 영향을 끼치지 않습니다.
---------------------------------
또 다른 예시입니다.
문법:
<assign> -> <id> = <expr>
<id> -> A | B | C
<expr> -> <id> + <expr>
| <id> * <expr> //참고로 이는 +와 *에 대해서 ambiguous한 문법이다. 잠시후 살펴보겠다.
| (<expr>)
| <id>
유도과정
A = B * ( A + C )
Leftmost Derivation인 경우 :
<assign> -> <id> =<expr>
-> A= <expr>
-> A = <id>*<expr>
-> A = B * <expr>
-> A = B * (<expr>)
-> A = B * (<id>+<expr>)
-> A = B * ( A + <expr>)
-> A = B * ( A + <id>)
-> A = B * ( A + C )
Rightmost Derivation인 경우 :
<assign> -> <id> =<expr>
-> <id> = <id> * <expr>
-> <id> = <id> * (<id>+<expr>)
-> <id> = <id> * (<id>+<id>)
-> <id> = <id> * (<id>+ C )
-> <id> = <id> * ( A + C )
-> <id> = B * ( A + C )
-> A = B * ( A + C )
Parse Tree
Parse Tree는 Derivation을 위계적으로 그린 것입니다.
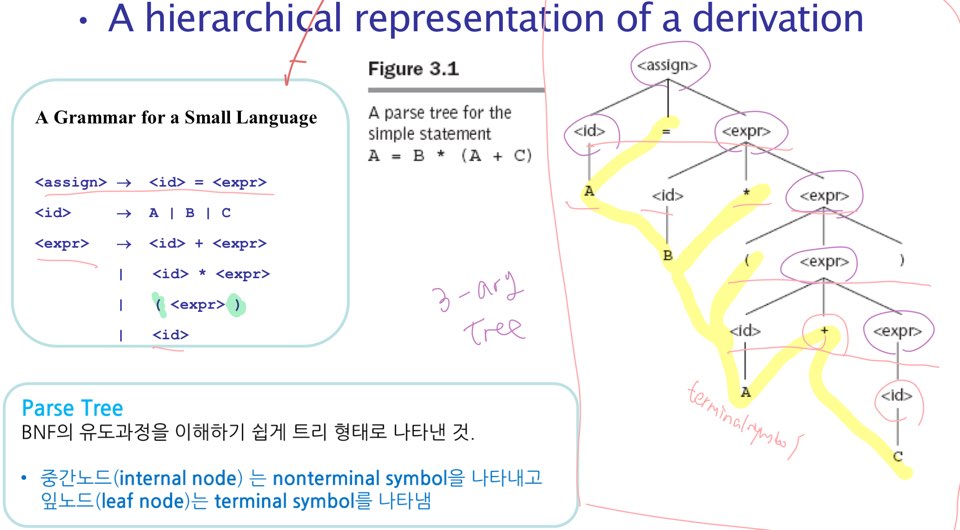
Ambiguous 한가?
하나의 sentence를 만드는 데 두 개 이상의 서로 다른 parse tree가 만들어질 수 있는 언어는 Ambiguous하다고 합니다.
어떤 언어가 모호함을 보이려면 단 하나의 sentence라도 모호함을 보이면 되고
어떤 언어가 모호함을 보이지 않으려면 모든 sentence가 모호함을 보여선 안됩니다.
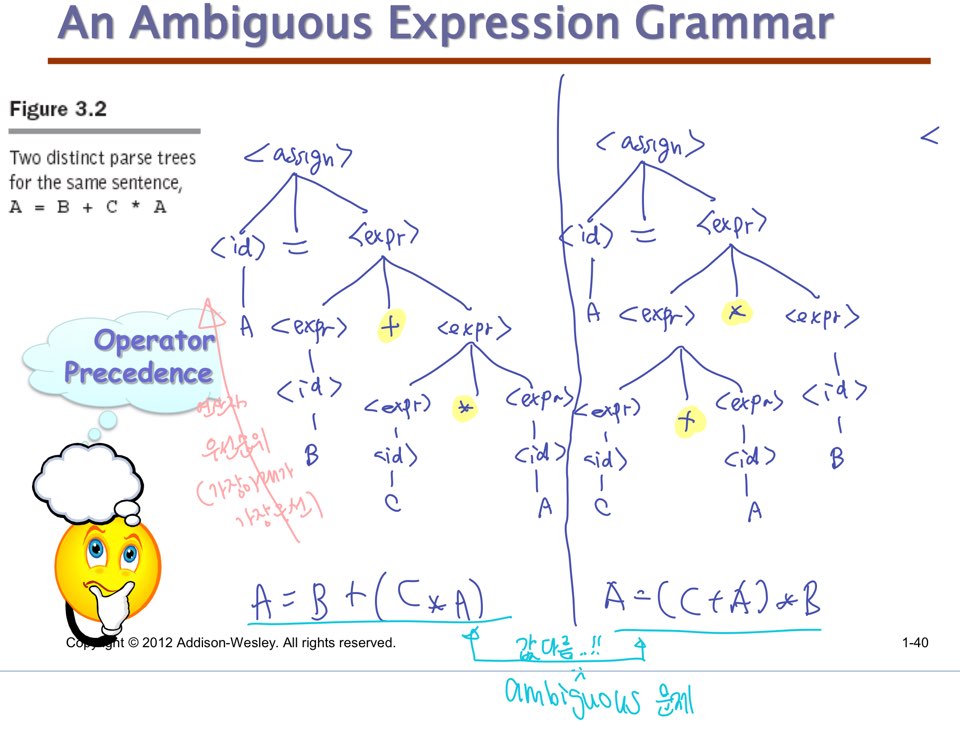
Operator Precedence
그래서 이때 중요한 개념이 연산자 우선순위입니다.
Parse tree로 그렸을 때 밑에 있을 수록 먼저 연산되므로 우선순위가 높습니다.
|
곱하기가 우선순위가 더 높은 경우 <assign> -> <id> := <expr> <id> -> A | B | C <expr> -> <expr> + <term> | <term> <term> -> <term> * <factor>//더 아래에 | <factor> <factor> -> ( <expr> ) | <id> |
더하기가 우선순위가 더 높은 경우 <assign> -> <id> := <expr> <id> -> A | B | C <expr> -> <expr> * <term> | <term> <term> -> <term> + <factor>//더 아래에 | <factor> <factor> -> ( <expr> ) | <id> |
|
Left recursive <assign> -> <id> := <expr> <id> -> A | B | C <expr> -> <expr> + <term> | <term> <term> -> <term> + <factor> | <factor> <factor> -> ( <expr> ) | <id> |
Right recursive <assign> -> <id> := <expr> <id> -> A | B | C <expr> -> <term> + <expr> | <term> <term> -> <factor> + <term> | <factor> <factor> -> ( <expr> ) | <id> |
if-then-else를 위한 unambiguous grammar
모호한 if-then-else 문법:
<if_stmt> -> if <logic_expr> then <stmt>
| if <logic_expr> then <stmt> else <stmt>
<stmt> -> <if_stmt> //이규칙이 추가되면 언어가 모호해진다.
if <logic_expr> then if <logic_expr> then <stmt> else <stmt>
에 대해 두 가지 parse tree가 나오게 됩니다.
else가 어떤 if와 연결되어야할지 모호해지기 때문입니다.
이를 이렇게 바꿔줘야합니다.
모호하지 않은 if-then-else 문법:
<stmt> -> <matched> | <unmatched>
<matched> -> if <logic_expr> then <matched> else <matched>
| 임의의 if가 아닌 문장
<unmatched> -> if <logic_expr> then <stmt>
| if <logic_expr> then <matched> else <unmatched>
EBNF(Extended BNF)
[]: optional parts
{}: repitions
(|): alternative parts
|
BNF <expr> -> <expr> + <term> | <expr> - <term> | <term> <term> -> <term> * <factor> | <term> / <factor> | <factor> <factor> -> <exp> ** <factor> | <exp> <exp> -> ( <expr> ) | <id> |
EBNF <expr> -> <term> { ( + | - ) <term> } <term> -> <factor> { ( * | / ) <factor> } <factor> -> { <exp> ** } <exp> <exp> -> ( <expr> ) | <id> |
가독성과 작성력을 높여준 BNF 버전이라고 보면 됩니다.
'프로그래밍언어' 카테고리의 다른 글
| [프로그래밍언어] Data Types_Union Types, Pointer and Reference Types, Type Checking, Strong Typing (0) | 2020.06.20 |
|---|---|
| [프로그래밍언어] Data Types_Primitive, Character String, Enumeration, Array Types (0) | 2020.06.19 |
| [프로그래밍언어]Subprograms (1) | 2020.06.19 |
| [프로그래밍언어] Names, Bindings, and Scopes (0) | 2020.06.18 |
| [Programming Language] Preliminaries (0) | 2020.06.17 |