
이전에 다루었던 메모리관리 편을 먼저 읽고 오시는 걸 추천해드릴게요
[운영체제 OS] - [운영체제/ OS] Main Memory 메모리 관리_ Address Binding, Segmentation, Paging, Memory Protection
[운영체제/ OS] Main Memory 메모리 관리_ Address Binding, Segmentation, Paging, Memory Protection
명령어가 실행되는 절차는 메인 메모리에서 명령어를 읽어와서 실행하고 결과를 다시 메모리에 저장해요. 하지만 메모리에 접근하는 과정은 단순하지 않고 cycle을 거쳐야 하고 stall(대기)상태에
hidemasa.tistory.com
Paging을 위한 메모리의 구조는 너무 크다는 단점을 가집니다.
메모리 비용이 너무 크고 메인메모리를 그렇게 연속적으로(contiguously) 할당하고 싶지 않을 때의 해결책으로
Hierarchical Paging
Hashed Page Tables
Inverted Page Tables 이 있습니다.
테이블을 여러 개 두어서
page table의 크기를 줄여서 메모리에 효율적이도록 하는 것입니다.
Hierarchical Paging
기본 paging 구조와 다르게 logical address table을 여러개로 나눈것이에요.
Two-level Page Table
계층적 paging 중 하나로 outer page table을 또 두어서 두 개의 page table을 가지는 구조에요.
논리주소(32bit)를 page number(22 bits)와 page offset(10 bits)로 나눕니다.
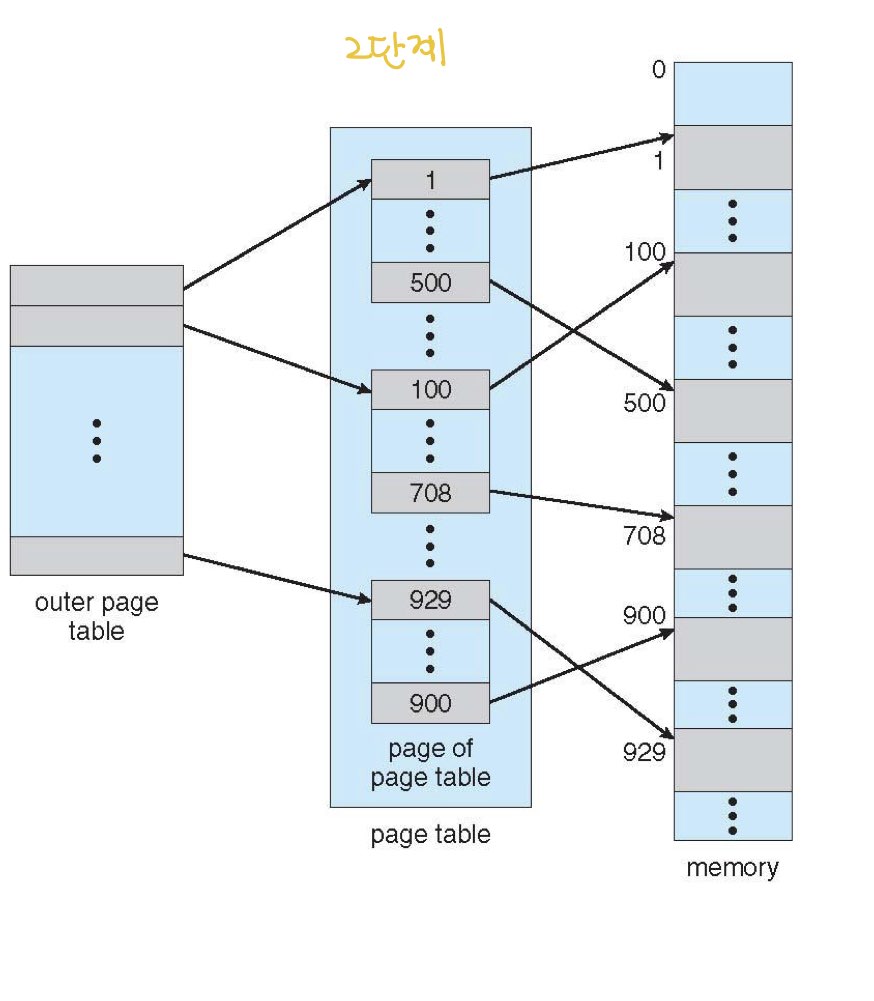

two-page table은 forward-mapped page table이라고도 불립니다. 점점 앞으로 찾아간다는 뜻에서.
그림의 p1은 outer page table, p2은 inner page table 입니다.
하지만 이 테이블은 64비트의 논리주소 공간에선 적합하지 않습니다.
해결책으로 두 번째 outer table을 하나 더 추가하면 하나의 physical memory 위치를 얻기 위해 4번의 메모리 접근을 필요로 하게 됩니다.
Hashed Page Table
32-bit의 주소공간에서 흔히 사용됩니다.
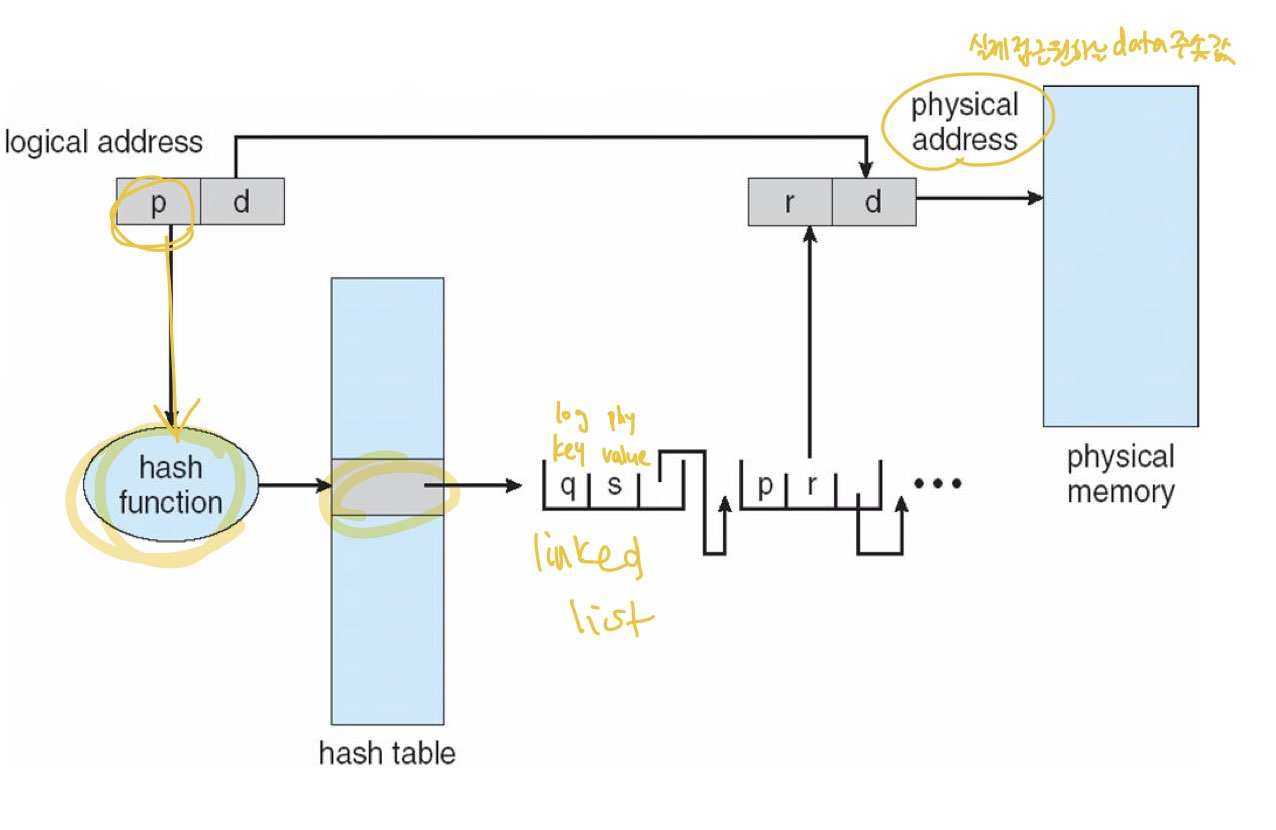
명령어 bit에서 page table의 index인 p를 hash function의 입력값으로 넣고 hash table에 결과값을 통과해 physical address를 찾습니다.
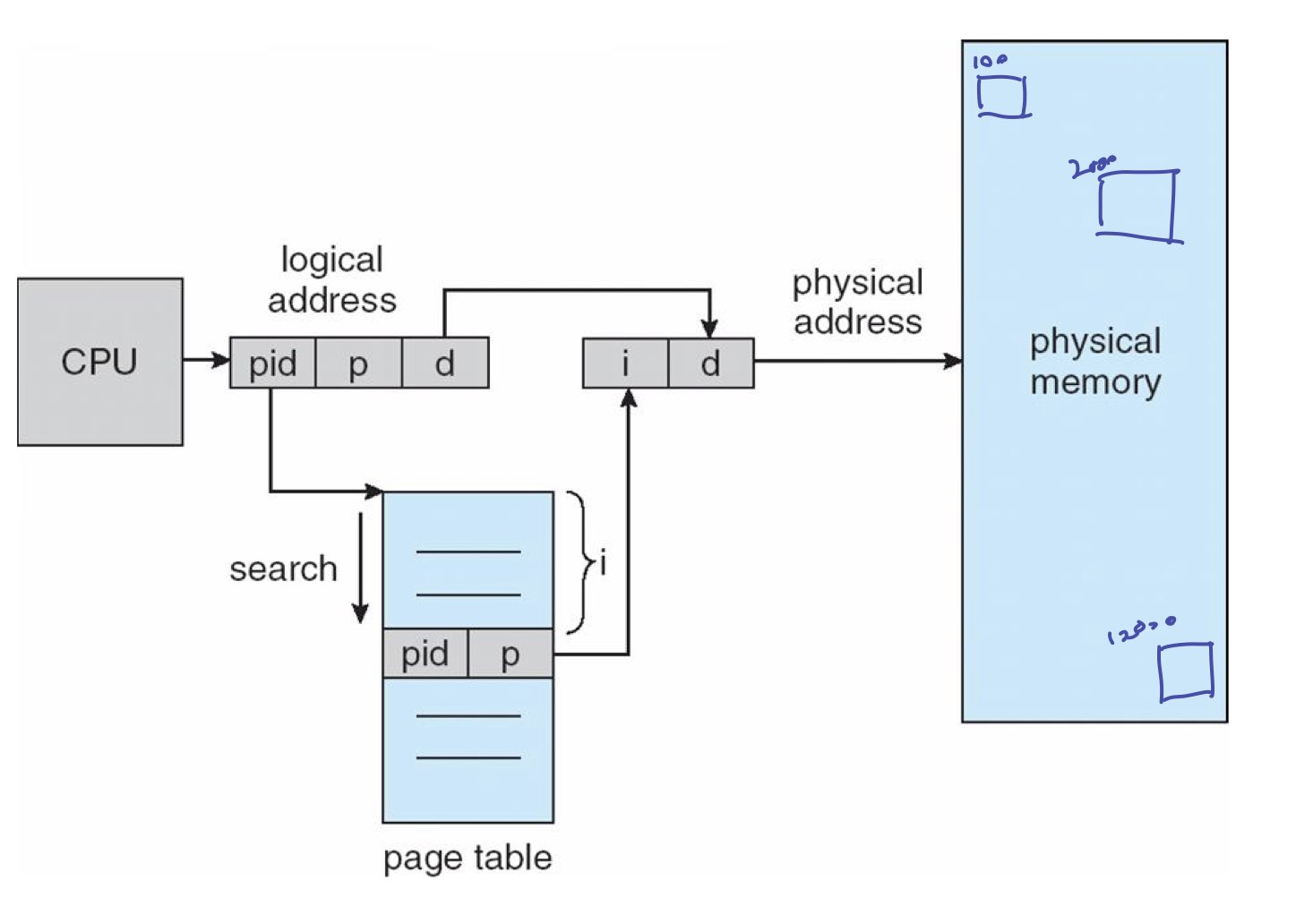
Inverted Page Table
앞에서 다룬 page table들은 논리주소대로 찾아갔는데
이 테이블은 logical의 개념을 뒤집어서 page table에 physical의 개념을 주로 다룬 것입니다. 내 pid와 physical address를 다 찾아서 physical offset를 더해서 구합니다.
단점은 overhead가 크다는 것인데, TLB와 동시에 접근함으로써 overhead를 좀 낮춰줍니다.
(TLB 개념은 이전 게시글에서 설명)
Swapping
프로세스 스케줄링에 대해 개념이 잘 안 잡혀있다면 스케줄링을 다룬 앞선 게시물을 보고 오시는 걸 추천할게요
[운영체제 OS] - [운영체제/OS] CPU Scheduling_ Multilevel Queue, Multilevel Feedback Queue 스케줄링
[운영체제 OS] - [운영체제/OS] CPU Scheduling_비선점, 선점, FCFS, SJF, Priority, RR 스케줄링
[운영체제/OS] CPU Scheduling_비선점, 선점, FCFS, SJF, Priority, RR 스케줄링
이전 글에서 간단하게 프로세스 스케줄링을 알아보았어요. [운영체제 OS] - [OS/운영체제] Process Scheduling 프로세스 스케줄링 [OS/운영체제] Process Scheduling 프로세스 스케줄링 프로세스- 프로그램이 �
hidemasa.tistory.com
Mid-term scheduler는 우선순위가 너무 뒤쳐진 애들을 위해 swapping을 합니다.
메모리와 디스크 사이를 out하고 in하는 것입니다.
프로세스를 임시적으로 메모리에서 백업공간(디스크의 swapping area)로 swap out하여 flush시키고 다른 프로세스로 대체합니다. 그리고는 다시 메모리로 다시 데려와서 이어서 execution합니다.

Address binding할 때 swapping이 일어나면 처음 논리주소를 기억하여 다시 엮어주는 작업이 필요합니다.
compile time과 load time에 해당하고 execution time이라면 신경쓰지 않아도 됩니다.
Address binding 에 대한 게시글은 앞선 게시글에서 설명하였습니다.
[운영체제 OS] - [운영체제/ OS] Main Memory 메모리 관리_ Address Binding, Segmentation, Paging, Memory Protection
[운영체제/ OS] Main Memory 메모리 관리_ Address Binding, Segmentation, Paging, Memory Protection
명령어가 실행되는 절차는 메인 메모리에서 명령어를 읽어와서 실행하고 결과를 다시 메모리에 저장해요. 하지만 메모리에 접근하는 과정은 단순하지 않고 cycle을 거쳐야 하고 stall(대기)상태에
hidemasa.tistory.com
Swapping을 포함하는 Context Switch time
만약 CPU할당하려는 다음 프로세스가 메모리에 없다면, 프로세스를 swap out하고 해당 프로세스를 swap in해야 합니다.
context switch time은 이때 매우 높아지게 되고
예를 들어 100MB의 프로세스를 디스크로 swap out하는 속도가 50MB/sec이라면
메모리->디스크의 swapping area 하는 swap out이 2초, swap in 또한 2초가 걸려
오버헤드가 엄청...나게 됩니다.
총 context switch time은 4초입니다.
메모리의 사이즈를 줄여서 이 swapping time을 줄일 수 있습니다. 실제 사용되는 메모리가 얼마인지 알 필요가 있습니다.
'운영체제 OS' 카테고리의 다른 글
| [운영체제/OS] Copy-on-Write와 Page Replacement (0) | 2020.12.05 |
|---|---|
| [운영체제/OS] Page Fault와 Demand Paging (0) | 2020.12.04 |
| [운영체제/ OS] Main Memory 메모리 관리1/2_ Address Binding, Segmentation, Paging, Memory Protection (0) | 2020.10.21 |
| [운영체제/OS] CPU Scheduling_ Multilevel Queue, Multilevel Feedback Queue 스케줄링 (0) | 2020.10.19 |
| [운영체제/OS] CPU Scheduling_비선점, 선점, FCFS, SJF, Priority, RR 스케줄링 (0) | 2020.10.19 |