
신경망(NN) 개념
사람의 신경망을 구성하는 신경세포 뉴런은 각각의 입력 신호에 최적의 가중치를 곱한 모든 합이 어느 임계값(Threshold)에 도달해야만 다음 뉴런으로 출력신호를 보내는 구조다.
이처럼 입력 신호를 받아서 특정임계값을 넘어서야만 출력을 생성하는 함수를 활성화함수라고 한다.
딥러닝 기초
딥러닝은 입력층, 은닉층, 출력층을 구축한 다음, 출력층의 오차를 기반으로 오차가 가장 작아지도록 각 층 사이에 존재하는 가중치(W2,W3..),각 층의 바이어스(b2,b3...)값을 최적화하는 머신러닝의 한 분야다.
참고로 딥러닝 구조에서 은닉층을 더 사용할수록 결과의 정확도가 높아진다고한다.
은닉층을 깊게할수록 정확도가 높아진다고 하여 '딥'용어가 붙었다.

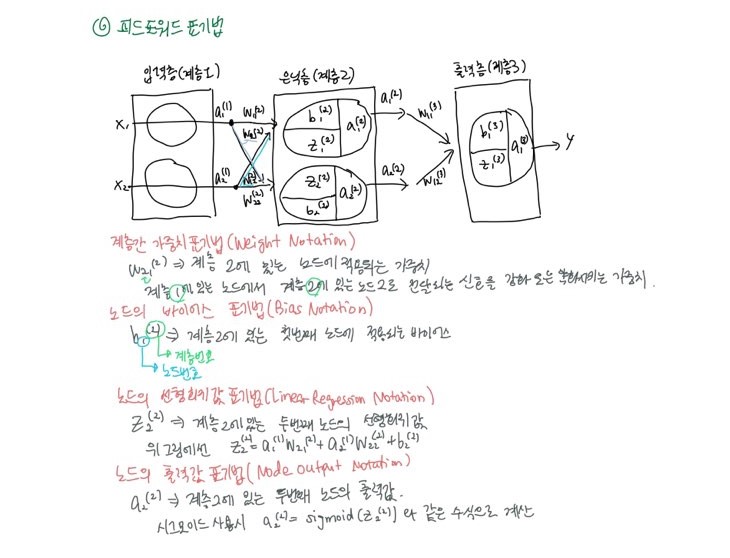
피드포워드(Feed Forward)
위의 그림이 피드포워드다.
입력층부터 출력층으로 데이터전달하면서 오차값을 계산하는 과정을 딥러닝에서 피드포워드라고 한다.
피드포워드 표기법(Notation)
입력층, 1개의 은닉층, 출력층으로 구성된 신경망으로 피드포워드 표기법을 설명할 수 있다.

딥러닝아키텍처로 XOR문제해결
[딥러닝/머신러닝]논리게이트 XOR문제(XOR problem)
Logistic Regression(미분)을 이용했을때 (추후에 Logistic Regression 게시글도 게시예정) XOR 게이트를 구현이 불가능하다. AND, OR, NAND게이트는 1개의 분류 시스템만으로도 구현가능하지만 XOR게이트는 여러
hidemasa.tistory.com
앞선 게시글에서 논리게이트 XOR문제를 NAND와 OR게이트 조합으로 해결하였다고 설명했다.
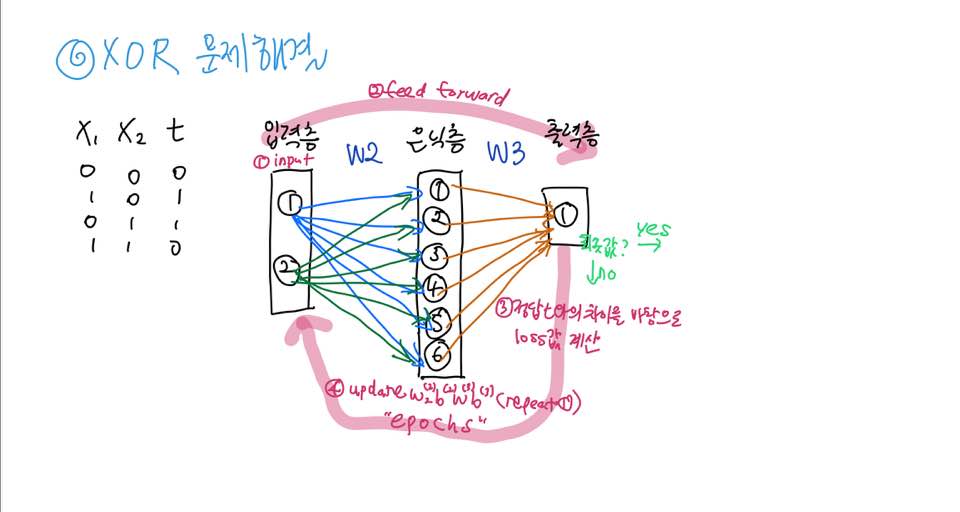
(은닉층의 노드는 여기서 6개로 정의하였는데 은닉층 노드수는 정해진 규칙이 없으므로 원하는만큼 만들수있다. 많을수록 학습속도가 느려지는 것은 감안할 것)
이와 같은 딥러닝 아키텍처로 XOR문제를 해결할 수 있다.
즉, (1)트레이닝 데이터를 입력데이터와 정답데이터로 분리한 다음, 피드포워드를 이용해서 출력층의 출력값을 바탕으로 손실함수값을 계산. 이후 (2)손실함수값이 최소가 될 때까지 가중치 W2,W3 ,바이어스 b2,b3을 최적화하는 과정이다.
(1)이 피드포워드, (2)가 epochs과정.
그렇다면 파이썬 코드로 구현해 실행해보자.
import numpy as np
def sigmoid(input_data):
return 1/(1+np.exp(-input_data))
def derivative(f, input_data):
delta_x=1e-4
ret=np.zeros_like(input_data)
it=np.nditer(input_data, flags=['multi_index'])
while not it.finished:
idx=it.multi_index
tmp=input_data[idx]
input_data[idx]=float(tmp)+delta_x
fx1=f(input_data)
input_data[idx]=float(tmp)-delta_x
fx2=f(input_data)
ret[idx]=(fx1-fx2)/(2*delta_x)
input_data[idx]=tmp
it.iternext()
return ret
class LogicGate:
def __init__(self, gate_name, x_data, t_data):
self.name = gate_name
# 입력 데이터, 정답 데이터 초기화
self.x_data = x_data.reshape(4,2) # 4개의 입력데이터 x1, x2 에 대하여 batch 처리 행렬
self.t_data = t_data.reshape(4,1) # 4개의 입력데이터 x1, x2 에 대한 각각의 계산 값 행렬
# 2층 hidden layer unit : 6개 가정, 가중치 W2, 바이어스 b2 초기화
self.W2 = np.random.rand(2,6) # weight, 2 X 6 matrix
self.b2 = np.random.rand(6)
# 3층 output layer unit : 1 개 , 가중치 W3, 바이어스 b3 초기화
self.W3 = np.random.rand(6,1)
self.b3 = np.random.rand(1)
# 학습률 learning rate 초기화
self.learning_rate = 1e-2
self.loss_val=self.feed_forward
print(self.name + " object is created")
def loss_val(self):
delta = 1e-7 # log 무한대 발산 방지
z2 = np.dot(self.x_data, self.W2) + self.b2 # 은닉층의 선형회귀 값
a2 = sigmoid(z2) # 은닉층의 출력
z3 = np.dot(a2, self.W3) + self.b3 # 출력층의 선형회귀 값
y = a3 = sigmoid(z3) # 출력층의 출력
# cross-entropy
return -np.sum( self.t_data*np.log(y + delta) + (1-self.t_data)*np.log((1 - y)+delta ))
#피드포워드, 손실함수값(loss value) 구해줌
def feed_forward(self):
delta=1e-7
#입력층->은닉층
z2=np.dot(self.x_data, self.W2)+self.b2 #은닉층 선형회귀값
a2=sigmoid(z2) #은닉층 출력
#은닉층->출력층
z3=np.dot(a2, self.W3)+self.b3 #출력층 선형회귀값
y=sigmoid(z3) #출력층 출력
#cross-entropy로 loss값 측정
return -np.sum(self.t_data * np.log(y+delta)+(1-self.t_data)*np.log(1-y+delta))
#수치미분을 이용하여 손실함수가 최소가 될때까지 학습하는 함수
def train(self):
f=lambda x:self.feed_forward()
print("Initial loss value=",self.loss_val())
for step in range(20001):
self.W2 -= self.learning_rate*derivative(f,self.W2)
self.b2 -= self.learning_rate*derivative(f,self.b2)
self.W3 -= self.learning_rate*derivative(f,self.W3)
self.b3 -= self.learning_rate*derivative(f,self.b3)
if(step%1000==0):
print("step=",step,"loss_value=",self.loss_val())
#미래값 예측
def predict(self,x_data):
z2=np.dot(x_data, self.W2)+self.b2
a2=sigmoid(z2)
z3=np.dot(a2, self.W3)+self.b3
y=sigmoid(z3)
if y<0.5:
result=0
else:
result=1
return y,result
#XOR데이터
x_data=np.array([[0,0],[0,1],[1,0],[1,1]])
t_data=np.array([0,1,1,0])
#train
XOR_obj=LogicGate("XOR_GATE",x_data,t_data)
XOR_obj.train()
print(XOR_obj.predict([0,0]))
print(XOR_obj.predict([0,1]))
print(XOR_obj.predict([1,0]))
print(XOR_obj.predict([1,1]))

'인공지능 AI' 카테고리의 다른 글
| [딥러닝/인공지능] 오차역전파(Back Propagation) (0) | 2020.06.07 |
|---|---|
| [딥러닝/인공지능]MNIST(필기체 손글씨) (0) | 2020.06.06 |
| [머신러닝/인공지능] 선형회귀_분류(Classification) (0) | 2020.06.06 |
| [머신러닝/인공지능] 선형회귀 예제 _단일변수/다변수 (0) | 2020.06.06 |
| [머신러닝/인공지능] 경사하강법(Gradient Descent Algorithm) (0) | 2020.06.06 |