
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
논문 선정 이유
모델 경량화 관련하여 참고하고 공부하기 위해서
Abstract
large-scale pre-trained 모델들로 Transfer Learning이 일반화된 NLP.
더 낮은 비용의 언어 모델링으로 사전학습을 하는 방법 제안.
We reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster.
1. Introduction
기존 대규모 언어 모델은 파라미터가 백만 개도 넘는다.
대규모 학습은 downstream task에서 높은 성능을 보여준다.
하지만, 비용 측면에서는 비효율적일 수 있다.
그래서 smaller language models pre-trained with knowledge distilation 제안.
2. Knowledge distillation
Transferring generalization capabilities
Knowledge distillation (sometimes also referred to as teacher-student learning) is a compression technique in which a small model is trained to reproduce the behavior of a larger model (or an ensemble of models). It was introduced by Bucila et al. and generalized by Hinton et al. a few years later. We will follow the latter method.
지도학습은 보통 high probability의 correct class와 near-zero probabilites의 나머지 class로 이루어진다.
But, some of these “almost-zero” probabilities are larger than the others, and this reflects, in part, the generalization capabilities of the model.
예를 들어, ‘책상 의자’가 ‘안락 의자’로는 분류될 수 있지만, ‘버섯’으로 분류되어서는 안된다.
Knowledge distillation prevents the model to be too sure about its prediction (similarly to label smoothing).
저자가 temperature 차용한 Hinton의 distilation 논문:Distilling the Knowledge in a Neural Network Copy of Distilling the Knowledge in a Neural Network (distillation)
Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome
arxiv.org
Rather than training with a cross-entropy over the hard targets (one-hot encoding of the gold class), we transfer the knowledge from the teacher to the student with a cross-entropy over the soft targets (probabilities of the teacher). Our training loss thus becomes:
Training Loss
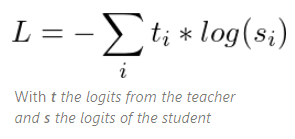
This loss is a richer training signal since a single example enforces much more constraint than a single hard target.
To further expose the mass of the distribution over the classes, Hinton et al. introduce a softmax-temperature:

When T → 0, the distribution becomes a Kronecker (and is equivalent to the one-hot target vector), when T →+∞, it becomes a uniform distribution. The same temperature parameter is applied both to the student and the teacher at training time, further revealing more signals for each training example. At inference, T is set to 1 and recover the standard Softmax.
다시 정리하자면,
loss는 3개의 loss 를 포함한다. 이 3개의 loss 는 linear combination으로 합쳐져 사용된다.
Cross entropy with teacher model's soft target
ti: teacher model 의 softmax-temparature 값
si: student model 의 softmax-temparature 값
softmax-temperature는 Hinton의 논문 그대로 차용.
학습이 끝나면 temparature를 1로 고정하여 기존 softmax 로 동작하게함.
Masked language model로 학습. (NSP는 제외함)
The final training objective is a linear combination of the distillation loss Lce with the supervised training loss, in our case the masked language modeling loss Lmlm [Devlin et al., 2018]. We found it beneficial to add a cosine embedding loss (Lcos) which will tend to align the directions of the student and teacher hidden states vectors.
기존 distillation 논문(teacher, student)에 **cosine embedding loss (Lcos)**을 추가했더니 성능이 더 좋아졌다. (이렇게 총 3개)
cosine embedding loss 는 teacher model 와 student 모델의 마지막 hidden state 의 vector 의 방향을 align 하게 해주는 효과가 있다.
s_hidden_states = s_hidden_states[-1] # (bs, seq_length, dim)
t_hidden_states = t_hidden_states[-1] # (bs, seq_length, dim)
mask = attention_mask.unsqueeze(-1).expand_as(s_hidden_states) # (bs, seq_length, dim)
assert s_hidden_states.size() == t_hidden_states.size()
dim = s_hidden_states.size(-1)
s_hidden_states_slct = torch.masked_select(s_hidden_states, mask) # (bs * seq_length * dim)
s_hidden_states_slct = s_hidden_states_slct.view(-1, dim) # (bs * seq_length, dim)
t_hidden_states_slct = torch.masked_select(t_hidden_states, mask) # (bs * seq_length * dim)
t_hidden_states_slct = t_hidden_states_slct.view(-1, dim) # (bs * seq_length, dim)
target = s_hidden_states_slct.new(s_hidden_states_slct.size(0)).fill_(1) # (bs * seq_length,)
loss_cos = self.cosine_loss_fct(s_hidden_states_slct, t_hidden_states_slct, target)
loss += self.alpha_cos * loss_cos
huggingface 의 구현체 일부. student 와 teacher 의 hidden state의 마지막 layer를 가져오고, cosine embedding loss 를 계산하여 기존 loss 에 linear combination하는것을 알 수 있다.
transformers/distiller.py at 3bf54172585d63ef1e0f20a2effe569b12e97b66 · huggingface/transformers
3. DistilBERT: a distilled version of BERT
Student architecture
DistilBERT- has the same general architecture as BERT.
실험해보니 last dimension of the tensor (hidden size dimension)와 number of layers를 변화를 주었을 때 number of layers에 따른 차이가 더 심해서, (dim vs #layers)
Thus we focus on reducing the number of layers.
Student initialization
an important element in our training procedure is to find the right initialization for the sub-network to converge.
We thus initialize our student, DistilBERT*,* from its teacher, BERT, by taking one layer out of two, leveraging the common hidden size between student and teacher.
student model의 weight 들을 어떻게 초기화 하는가에 따라 모델의 성능이 많이 바뀐다. distillBERT 에서는 teacher model 과 student model 의 dim 은 동일하기 때문에, teacher model의 weight 를 그대로 복사하여 사용한다.
4. Experiments


MLM 제거보다 two distillation losses가 성능에 더 큰 부분을 차지한다.
요약
BERT + Knowledge Distillation = DistilBERT
다른 논문들처럼 특정 태스크 전용으로 KD를 적용하는게 아니라
Pre-Training 단계에서 부터 KD를 적용해서
General Purpose Language Representation Model을 만들었다는 점.
비용적 측면에서 경량화 작업이 필요할 때, 해당 서비스에 매우 유용하게 사용 가능할듯.
학습방법: KD 모델 압축 기술
Student + Teacher Loss
즉, 학생은 선생의 'soft target probability'를 배운다.
선생 모델이 출력하는 확률 분포 자체를 배움으로써
학생 모델이 자신 보다 복잡한 모델들만이 배울 수 있는 signal 또한 함께 배울 수 있다.
- ⇒해당 내용에 대한 Hinton 논문 읽기.
Final Training Objective = Distillation Loss(CE) + Masked Language Modeling Loss + Cosine Embedding Loss