
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
We call our approach ELECTRA for “Efficiently Learning an Encoder that Classifies Token Replacements Accurately.”
핵심요약
ELECTRA achieves higher accuracy on downstream tasks when fully trained.
replaced token detection → pre-training
GAN이랑 비슷한 구조.
하지만 generator를 maximum likelihood로 train. (기존GAN: adversarial하게 학습)
왜냐하면 text는 adversarial하게 하기가 쉽지 않음..
generator G: MLM의 단어를 replace
discriminator D: 모든 단어 보면서 real fake 구별.

Abstract
Introduction

기존의 MLM이 아닌 Replaced Token Detection 도입!
Method
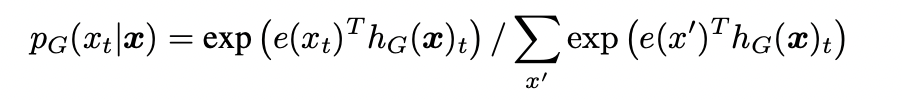
- generator G
MLM 수행.
Random position
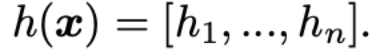
Xt = [MASK]
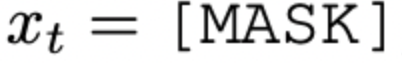
- discriminator D
predicts whether the token Xt is ‘real’.

- GAN과의 차이점:
generator를 maximum likelihood로 train.
즉 discriminator를 속이는게 아니고 generator 생성한 거를 fake로 간주하는게 아니다.
noise vector를 input으로 generator에 넣지 않음.
adversarial하게 학습하지 않음. (backpropagate하기 어려워지기 때문.)
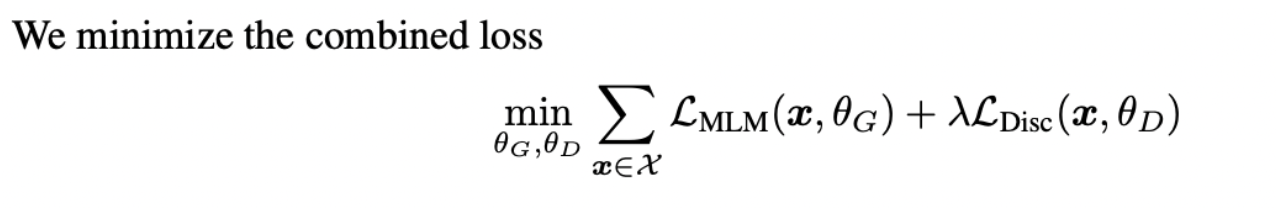
We don’t back-propagate the discriminator loss through the generator (indeed, we can’t because of the sampling step).
After pre-training, we throw out the generator and fine-tune the discriminator on downstream tasks.
Experiments
Experimental Setup
Our model architecture and most hyperparameters are the same as BERT’s. For fine-tuning on GLUE, we add simple linear classifiers on top of ELECTRA. For SQuAD, we add the question answering module from XLNet on top of ELECTRA, which is slightly more sophisticated than BERT’s in that it jointly rather than independently predicts the start and end positions and has a “answerability” classifier added for SQuAD 2.0.
Model Extensions
- Weight Sharing
Generator 와 Discriminator 사이에서 Weight Sharing.
If the generator and discriminator are the same size, all of the transformer weights can be tied. However, we found it to be more efficient to have a small generator, in which case we only share the embeddings (both the token and positional embeddings) of the generator and discriminator.
Generator가 작으면 효과적. + Only share the Embeddings
- Small Generators, Training Algorithm
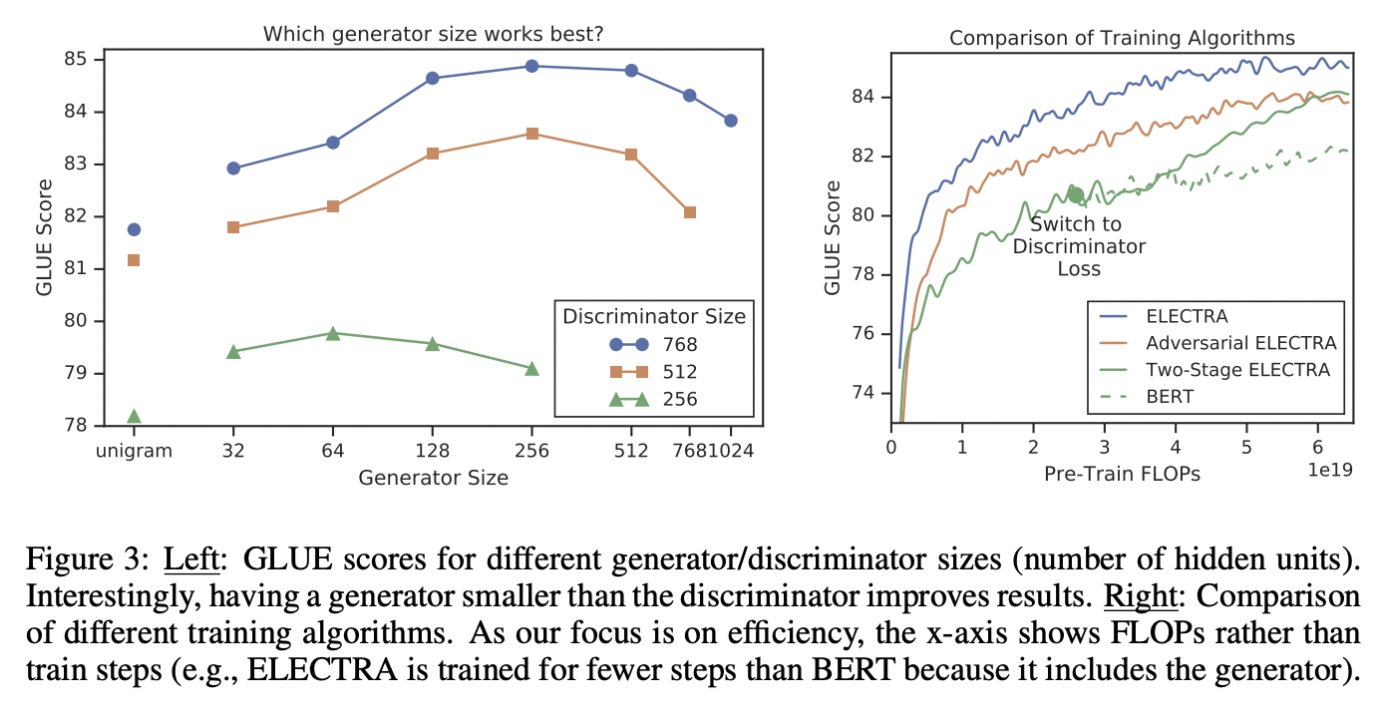
왼쪽 그림이 Small Generators.
All models are trained for 500k steps, which puts the smaller generators at a disadvantage in terms of compute because they require less compute per training step. Nevertheless, we find that models work best with generators 1/4-1/2 the size of the discriminator. We speculate that having too strong of a generator may pose a too-challenging task for the discriminator, preventing it from learning as effectively.
generator가 discriminator의 1/4-1/2 크기에서 성능이 가장 좋았음.
오른쪽 그림이 Training Algorithms.

실험 방법.
- generator만 MLM에 대해 n만큼 학습
- discriminator를 generator의 weight만큼 초기화. 그리고 generator의 weight를 freeze.
- Small Models
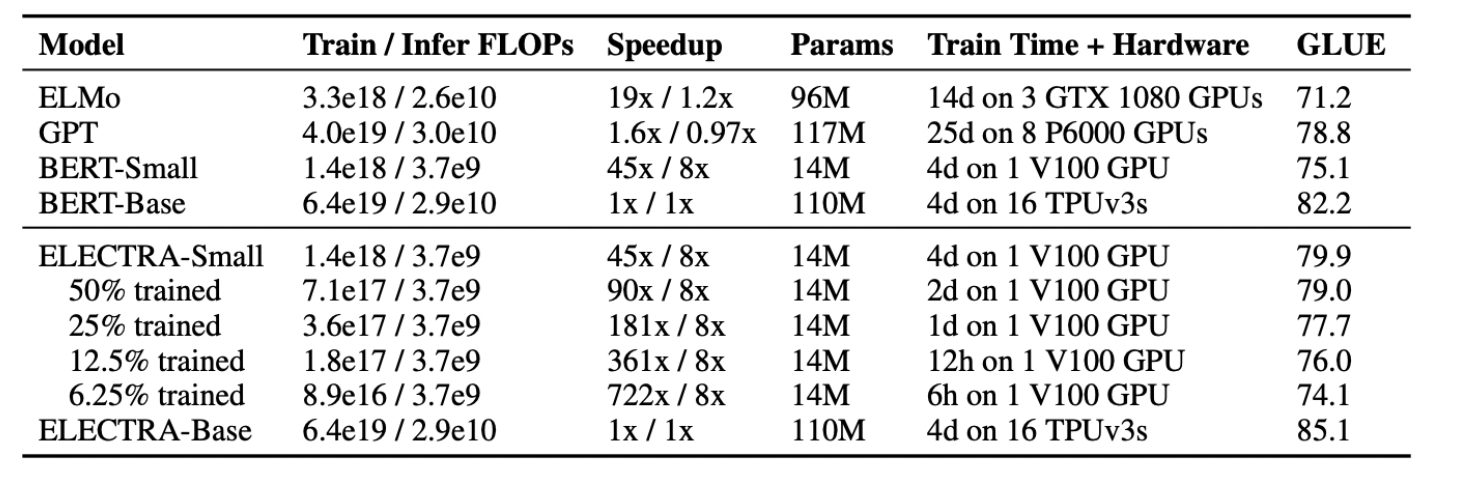
As a goal of this work is to improve the efficiency of pre-training, we develop a small model that can be quickly trained on a single GPU.
Small은 79.9 높은 성능.
Base는 BERT-small, base 도 둘다 이김.
- Large Models
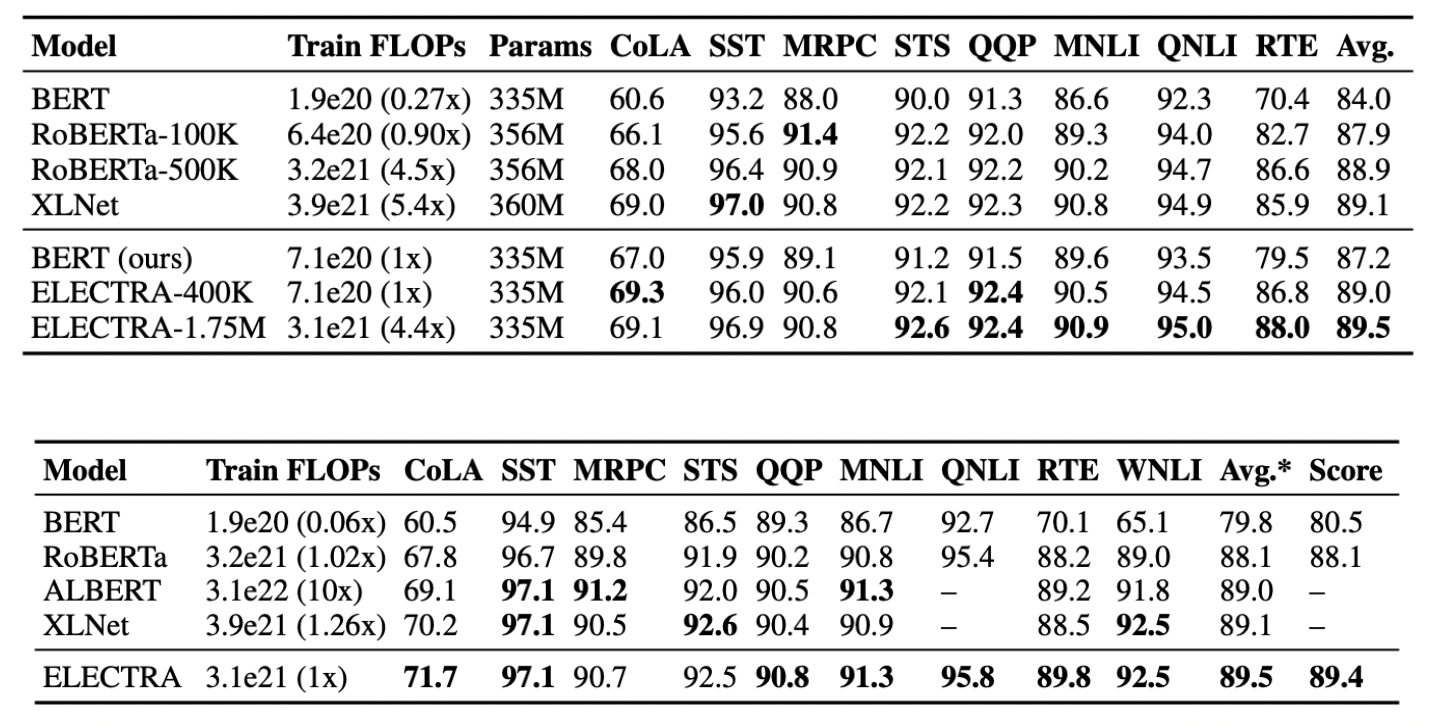
Comparison of large models on the GLUE dev set. ELECTRA and RoBERTa are shown for different numbers of pre-training steps, indicated by the numbers after the dashes. ELECTRA performs comparably to XLNet and RoBERTa when using less than 1/4 of their pre-training compute and outperforms them when given a similar amount of pre-training compute. BERT dev results are from Clark et al. (2019).
GLUE test-set results for large models. Models in this table incorporate additional tricks such as ensembling to improve scores (see Appendix B for details). Some models do not have QNLI scores because they treat QNLI as a ranking task, which has recently been disallowed by the GLUE benchmark. To compare against these models, we report the average score excluding QNLI (Avg.*) in addition to the GLUE leaderboard score (Score). “ELECTRA” and “RoBERTa” refer to the fully-trained ELECTRA-1.75M and RoBERTa-500K models.
- Efficiency Analysis
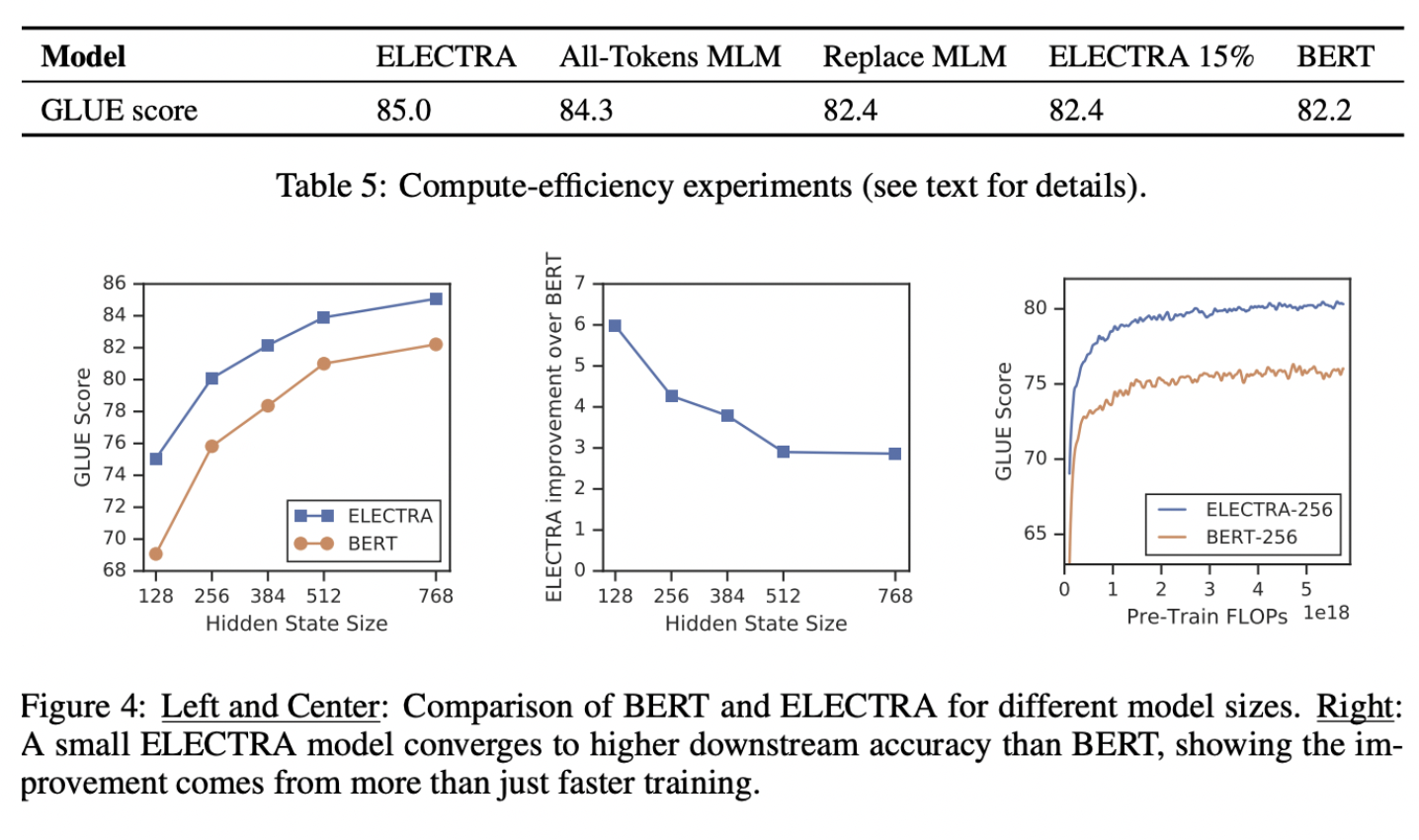
small subset의 token 학습으로 MLM은 비효율적이라고 했었으나,
이 경우는 다르다.
결국 어차피, large number of input tokens를 받기 때문.
다른 pre-training object
- Electra 15%
- Replace MLM
- All-Tokens MLM
결과적으로, Table 5에 따라,
First, we find that ELECTRA is greatly benefiting from having a loss defined over all input tokens rather than just a subset: ELECTRA 15% performs much worse than ELECTRA. Secondly, we find that BERT performance is being slightly harmed from the pre-train fine-tune mismatch from [MASK] tokens, as Replace MLM slightly outperforms BERT.
요약하면, All-Tokens MLM이 BERT와 ELECTRA의 격차를 좁혔다.
All-Tokens, 적은 양의 pre-train - fine-tune mismatch가 ELECTRA의 많은 개선을 이루었다.
모델이 작아질수록 ELECTRA 성능 높아짐.
그리고 full-trained 했을 때, BERT보다 높은 정확도 달성.
⇒ 컴퓨팅 리소스가 작은 연구환경에서 도움이 될 수 있겠다.
Conclusion
We have proposed replaced token detection, a new self-supervised task for language representation learning. The key idea is training a text encoder to distinguish input tokens from high-quality negative samples produced by an small generator network. Compared to masked language modeling, our pre-training objective is more compute-efficient and results in better performance on downstream tasks. It works well even when using relatively small amounts of compute, which we hope will make developing and applying pre-trained text encoders more accessible to researchers and practitioners with less access to computing resources. We also hope more future work on NLP pre-training will consider efficiency as well as absolute performance, and follow our effort in reporting compute usage and parameter counts along with evaluation metrics.