
ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION
https://arxiv.org/abs/2107.02137
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly,
arxiv.org
논문선정이유
바이두에서 개발한 ERNIE 3.0
바이두는 프레임워크 PaddlePaddle을 통해 NLU모델을 계속 공개해왔다.
ABSTRACT
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 [1] and GPT-3 [2] have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE [3] benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).

Related Works
Large-scale Pre-trained Models
대규모 사전학습 모델이 학계와 산업계에서 높은 성능을 보이며 주목받고 있다.
Knowledge Enhanced Models
사전학습 언어모델은 대규모 말뭉치로부터 구문, 의미적 지식을 학습하지만 실세계의 지식은 부족하다. 최근, 사전학습 모델에 이러한 상식을 부여하고자 하는 시도가 여럿 있었는데 대표적으로 지식 그래프를 사용하는 방법이 있다. WKLM, KEPLER, CoLAKE, ERNIE 1.0, CALM, K-Adapter 등이 발표되었다.
ERNIE 3.0
Universal Representation Module
ERNIE 3.0 uses a multi-layer Transformer-XL [34] as the backbone network like other pre-trained models such as XLNet [35], Segatron [36] and ERNIE-Doc [37], in which Transformer-XL is similar to Transformer but introduces an auxiliary recurrence memory module to help modelling longer texts.
범용 semantic feature 추출기로서 작동하며(multi-layer Transformer가 될 수 있다) 모든 task에서 공유되는 parameter이다.
Task-specific Representation Module
the task-specific representation module is also a multi-layer Transformer-XL, which is used to capture the top-level semantic representations for different task paradigms.
task-specific feature를 추출하는 부분으로 task마다 다른 parameter를 가진다.
Pre-training Tasks
Word-aware Pre-training Tasks
Knowledge Masked Language Modeling
Document Language Modeling
Structure-aware Pre-training Tasks
Sentence Reordering
ERNIE 2.0에서 제안된 task로 모델은 순서가 뒤바뀐(permuted) 문장들의 원래 순서를 찾아내야 한다.
Sentence Distance
NSP(Next Sentence Prediction) task의 확장판으로 문장 간의 관계를 3가지 분류(인접 문장/인접하지는 않았으나 같은 문서 내에 존재/서로 다른 문서에 존재) 중 하나로 특정해야 한다.
Knowledge-aware Pre-training Tasks
Universal Knowledge-Text Prediction
an extension of knowledge masked language modeling. While knowledge masked language modeling only requires unstructured texts, universal knowledge-text prediction task requires both unstructured texts and knowledge graphs.
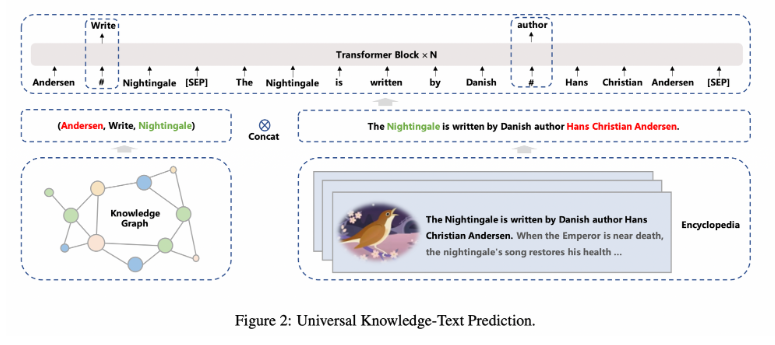
In detail, we build the corpus for ERNIE 3.0 based on that from ERNIE 2.0 (including baike, wikipedia, feed and etc), Baidu Search (including Baijiahao, Zhidao, Tieba, Experience), Web text, QA-long, QA-short, Poetry 2&Couplet 3, Domain-specific data from medical, law and financial area and Baidu knowledge graph with more than 50 million facts.
Experiments
- Sentiment Analysis: NLPCC2014-SC 6 , SE-ABSA16_PHNS 7 , SE-ABSA16_CAME, BDCI2019 8 . • Opinion extraction: COTE-BD [50], COTE-DP [50], COTE-MFW [50]. • Natural Language Inference: XNLI [51], OCNLI [45], CMNLI [45]. • Winograd Schema Challenge CLUEWSC2020 [45]. • Relation Extraction: FinRE [52], SanWen [53]. • Event Extraction: CCKS2020 9 . • Semantic Similarity: AFQMC [45], LCQMC [54], CSL [45], PAWS-X [55], BQ Corpus [56]. • Chinese News Classification: TNEWS 10, IFLYTEK [57], THUCNEWS 11, CNSE [58], CNSS [58]. • Closed-Book Question Answering: NLPCC-DBQA 12, CHIP2019, cMedQA [59], cMedQA2 [60], CKBQA 13, WebQA [61]. • Named Entity Recognition: CLUENER [45], Weibo [62], OntoNotes [63], CCKS2019 14 . • Machine Reading Comprehension: CMRC 2018 [64], CMRC2019 [65], DRCD [66], DuReader [67], Dureaderrobust [68], Dureaderchecklist, Dureaderyesno 15, C3 [69], CHID [70]. • Legal Documents Analysis: CAIL2018-Task1 [71], CAIL2018-Task2 [71]. • Cant Understanding: DogWhistle Insider, DogWhistle Outsider[72]. • Document Retrieval: Sogou-log [73].
- Text Summarization: LCSTS [10] • Question Generation:KBQG 16, DuReader-QG [67], DuReaderrobust-QG [68]. • Closed-Book Question Answering: MATINF-QA [74]. • Math: Math23K [75]. • Advertisement Generation: AdGen [76]. • Translation: WMT20-enzh [77]. • Dialogue Generation: KdConv [78].