
일반적인 예측 모델로 SVM과 유사성이 높습니다.
방법론적 특성상 MF와 같은 행렬분해 방식의 추천 알고리즘이 확장된 것입니다.


Factorization Machine은 매우 sparse한 데이터를 다루고,
사용자와 아이템 정보 외의 다양한 feature들을 포함해서 활용합니다.
사전에 소개했던 MF는 사용자와 아이템 정보, rating 정보만 활용했던 것과 다릅니다.
MF와 FM이 이름도 비슷해서 헷갈릴 수 있는데, FM은 Polynomial Regression(다항 회귀)에 가깝습니다.
X에서 Y를 예측하는 일반적인 지도학습 모델로,
NeuralCF와의 차이는 - NeuralCF는 사용자와 아이템 정보만으로 target을 예측하는 모델입니다.
MF(Matrix Factorization)와 NeuralCF 게시글 보러가기 >>
[AI/이론] 딥러닝 기반의 추천시스템 Recommender System, 행렬분해(MF), NeuralCF, GMF, MLP
딥러닝 추천시스템 모델 기반 협업 필터링 - MF, 딥러닝 - MLP: 주로 행렬분해(Matrix Factorization) 개선 ex) NeuralCF, DeepFM, Wide&Deep Learning - AutoEncoder: 차원축소 등 딥러닝 ex) RBM-Rec, AutoRec, CDAE - RNN/CNN: Sequen
hidemasa.tistory.com
일반적인 선형모델은 평균으로 회귀합니다.
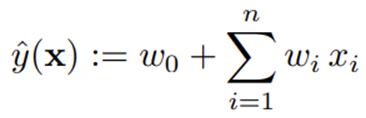
SVM모델은 고차항과 interaction항을 포함할 수 있지만, 학습이 느리고 차원의 저주 문제가 발생할 수 있습니다.
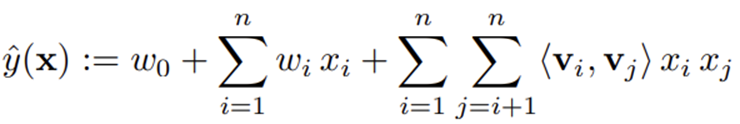
**차원의 저주 현상: 차원이 증가하면서 학습데이터 수가 차원 수보다 적어져서 성능이 저하되는 현상**
MF모델: 저차원에서 interaction항을 포함하지만, 다른 정보를 포함하기는 어렵습니다.
즉, 일반적인 지도학습 모델의 형태는 아닙니다.
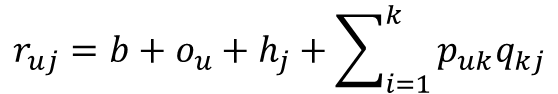
FM 모델
Interaction항의 계수를 잠재 공간에서 추출합니다.
SVM이 Dense Parametrization을 사용하는 것과 달리 FM은 factorized parametrization 방법을 사용합니다.
다음의 식은 2개 특성 사이의 관계를 고려하는 2-way(d=2) Factorization machine 입니다.
다항회귀 계산과 상당히 유사한데,
coefficient 대신 특성마다 latent space로의 매핑을 진행하고, latent space에서의 내적을 계산합니다.
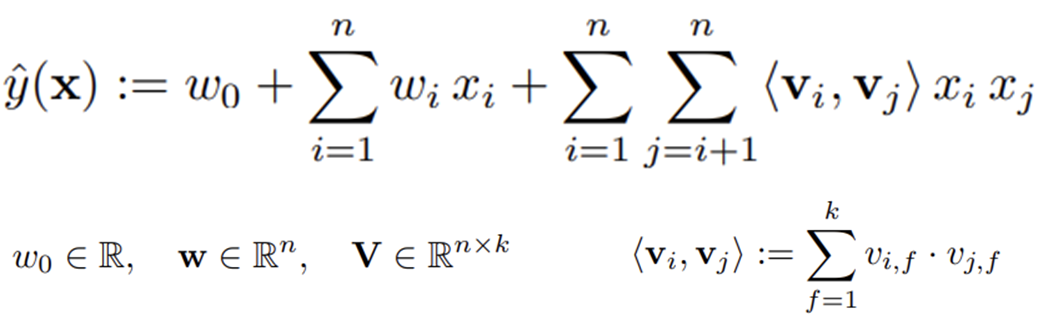
각각의 변수를 f 차원의 latent Factor로 매핑하여, 변수간의 상관관계를 Matrix Factorization과 같이 Latent Factor의 내적으로 모델링합니다.
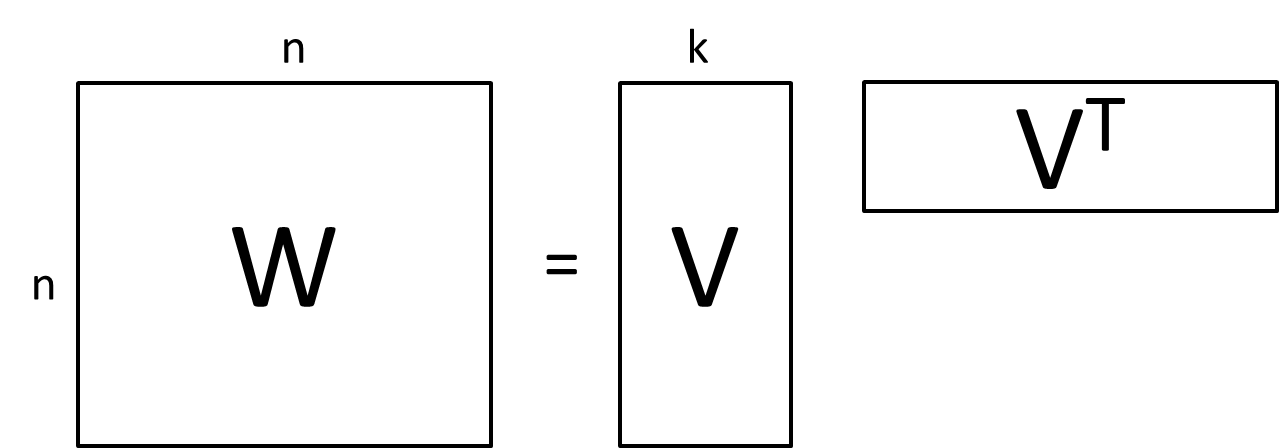

FM은 데이터가 Sparse한 경우에 적합합니다.
다항회귀를 진행해서 비용이 n*k^2를 예상할 수 있지만, 실제로는 비용이 nk가 나옵니다.
따라서 O(nk)의 linear complexity를 가진다는 장점이 있습니다.

변수 사이의 Interaction을 추정할 수 있습니다.
Training:

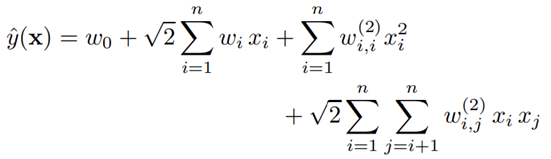
2-way가 아닌 d-way로 계산한 식을 봐도 O(nk) 이내로 계산됩니다.
실험: SVM과의 비교

sparse한 Netflix 데이터에서 차원에 따른 성능을 비교하였습니다.
그 결과 SVM은 Sparse한 환경에서 학습에 실패하였으며, FM은 차원 증가에 따른 학습이 잘 진행되었음을 확인할 수 있습니다.
정리
FM 모델은 SVM과 Matrix Factorization의 장점을 모두 가지고 있습니다.
SVM과 공통점: 유저, 아이템을 포함한 다양한 특성이 하나의 벡터안에 공존하고 있으며 sparse한 데이터의 interaction을 다룬다. 즉, 유저 아이템 정보 외의 추천시스템 정보를 활용할 수 있다.
SVM과의 차이점: FM도 SVM의 polynomial kernel과 비슷한 다항회귀 계산과 유사하게 모델링을 하나, SVM의 dense 파라미터 대신 factorized 파라미터를 사용한다.
MF과의 공통점: 평점과 같은 상호관계를 예측한다.
MF과의 차이점: Matrix Factorization이 user, item, rating 만을 사용하는 것과는 다르게, FM은 위의 그림과 같이 다양한 Feature를 concatenate하여 하나의 feature vector로 사용한다.
비용효율성: Linear Complexity O(nk)로 2-way 뿐 아니라 d-way에서도 굉장히 비용효율적인 메리트를 보인다.