
협업 필터링(Collaborative Filtering)
- 사용자 행동 데이터로 아이템 추천.
- 유사 사용자 그룹에서 공통 관심 아이템을 추천.
- 대규모 데이터 필요(데이터 적은 경우, 신규 아이템/사용자에는 어려움)
- 새로운 아이템 추천 가능.
• Memory Based Approach(메모리 기반 방식)
- User-based Filtering : target user와 유사한 user들의 아이템 선호 기반 추천
- Item-based Filtering: target item과 유사한 item들에 대한 사용자 추천
• Model Based Approach
- 사용자-아이템 평점 표현한 수학적 모델로부터 데이터 학습.
- 행렬 분해(Matrix Factorization): MF, SVD, NMF 등Spotify는 어떻게 사람들에게 음악을 추천할까?
- Collaborative Filtering 협업 필터링 모델, 사용자와 다른 사용자들의 데이터를 다루는 역할
- Natural Language Processing (NLP) 자연어처리 모델, 텍스트를 분석하는 역할
- Audio 모델, raw audio tracks를 분석하는 역할.

1. 협업필터링 추천시스템 Collaborative Filtering Recommender Systems:
Model-based Collaborative Filtering
넷플릭스와 다르게, 스포티파이는 별점랭킹점수를 사용하지 않기 때문에, 별점랭킹 데이터를 사용하지 않습니다.
대신 implicit feedback 데이터를 사용하는데, 이는 stream counts입니다.
예를 들어, 사용자 A가 트랙 1,2,3,4를 즐겨듣고, 사용자 B가 트랙 2,3,4,5를 즐겨듣는다고 하자.
그러면 협업 필터링은 데이터를 분석하여서 "두 사용자 모두 트랙 2,3,4를 즐겨듣는군.. 둘은 비슷한 사용자로 아직 들어보지 않은 다른 트랙도 즐겨들을 거야" 라고 판단을 하는 것이다.
그러면 사용자 B가 아직 들어보지 않은 트랙은 트랙 1이다. 그리고 사용자 A는 트랙 4를 추천해볼만하다.
하지만 스포티파이가 몇천만의 사용자 데이터를 어떻게 다룰까요?
파이썬 라이브러리를 통한 행렬을 이용하는 것입니다.
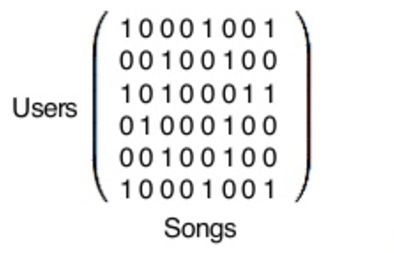
그리고 이러한 행렬을 만들어 볼 수 있습니다.
각 행과 열은 스포티파이의 사용자들과 트랙들을 대표합니다.
그리고 파이썬 라이브러리가 이에 대해 MF (Matrix Factorization) 을 수행합니다.


2. 자연어처리 (NLP)
스포티파이가 추천시스템 모델로 사용하는 것은 자연어처리(NLP)모델들입니다.
트랙 메타데이터, 뉴스기사, 블로그, 인터넷 텍스트 데이터들 - 데이터를 사용합니다.
스포티파이는 지속해서 특정 아티스트나 노래들에 대한 블로그포스트나 기사들(여론)에 대해 크롤링을 진행합니다.
해당 아티스트나 노래들에 대해 어떤 특정 언어가 주로 사용되는지, 관련된 어떤 아티스트들이 주로 거론되는지 등을 분석합니다.
각 아티스트와 노래들은 매일 top terms들이 매핑되는데, 이에 대해 중요 관계성 따라 가중치를 매깁니다.
쉽게 말하자면, 어떤 노래나 가수에 대해 해당 term으로 설명할 수 있다는 거죠.

3. Audio 모델: Raw Audio Models
사실 협업필터링과 NLP 모델만으로도 추천시스템의 성능은 좋지만,
하나 더 추가하면 노래 추천 성능이 더 올라가지 않겠어요?
게다가 오디오 모델은 새로운 노래에 대해서 학습을 할 수 있다는 장점이 있습니다.
예를 들어, 신예 싱어송라이터 가수가 노래를 등록합니다.
아무래도 언더그라운드 가수다보니, 트랙에 대한 사용자 리스닝횟수가 50번 안팎입니다.
그렇다면 협업필터링을 사용하기가 조금 애매하죠?
게다가 블로그나 뉴스기사 등 인터넷에 해당 신예가수에 대한 데이터도 아직 없을테니, NLP도 애매합니다..
하지만 오디오 모델은 이런 언더그라운드 트랙과 대중적인 인기트랙에 차별을 두지 않습니다.
오디오 데이터는 CNN을 사용합니다.

그리고 스포티파이는 HDFS 구조를 사용하여 이러한 대용량 데이터 저장소를 관리합니다.
----------------
이렇게 스포티파이는 별점랭킹 좌표가 없으므로, Model-based 협업 필터링을 사용했습니다.
사용자-아이템 평점 표현한 수학적 모델로부터 데이터 학습하는 방법이 있고,
Memory-based Collaborative Filtering 기법 중 하나인 User-based Collaborative filtering을 사용하는 방법도 있습니다.
User-based Collaborative filtering(Memory-based Collaborative Filtering)
메모리 기반 협업 필터링은 사용자가 매긴 랭킹 데이터와 아이템이나 사용자간 유사성을 계산합니다.
- User-based Filtering : target user와 유사한 user들의 아이템 선호 기반 추천
- Item-based Filtering: target item과 유사한 item들에 대한 사용자 추천
사용자 u가 아이템 i에 대한 평점 = 유사한 사용자들 평점 집합

U는 top N 사용자들이 아이템 i를 평점 매긴 사용자 u와 가장 유사했다는 것을 뜻합니다.

k는 normalizing factor로

그리고 추천결과를 생성하는 식에 대해 알아보겠습니다.
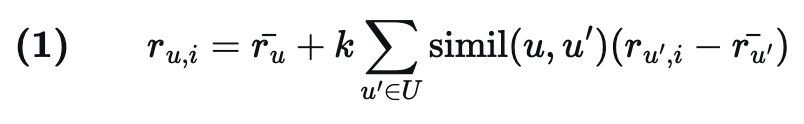
우변의 첫번째 항: ru¯ 는 u가 평점을 매긴 아이템들에 대한 사용자 u의 평균 평점입니다.
우변의 두번째 항: neighborhood-based algorithm은 두 사용자 또는 아이템 간의 유사성을 계산하고,
모든 랭킹의 가중 평균을 취하여 사용자에 대한 예측을 생성합니다.
아이템 또는 사용자 간의 유사성 계산에는 Pearson 상관관계 및 벡터 코사인 유사성과 같은 여러 측정값이 사용됩니다.
사용자 x와 y의 코사인 유사성 계산은:
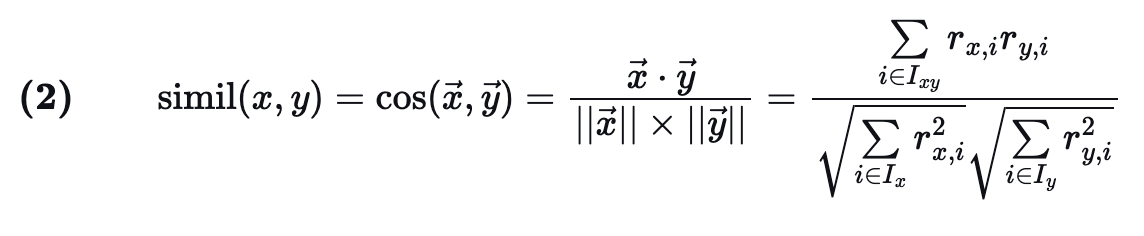
Ixy 는 사용자 x와 y가 모두 평점을 매긴 아이템 집합입니다.
사용자 기반 top-N recommendation 알고리즘은 유사성 기반 벡터 모델을 사용합니다.
top k 유사한 사용자들을 식별하기 위해 계산을 하고, 상응하는 사용자-아이템 행렬을 가산하여서
추천할 아이템 집합을 결과로 산출합니다!
(+)
만약에 (1) 식을 (1-1)식으로 바꾼다면 추천 결과가 어떻게 달라질까요?

(1-1) 식은 bias 텀 없이 이웃들의 평점 평균으로만 해당 사용자의 평점을 계산하는 것을 의미합니다.
하지만 사용자의 평점 bias가 서로 다르고 그 점이 반영되지 않는다면, 제대로 된 추천 결과(예상 평점)가 계산되지 않을 수 있습니다.
예를 들어, 사용자의 평점 평균이 2점이고, 최근접 이웃들의 평점 평균이 4.5점이라면,
평균 3점 정도의 아이템에 대해 최근접 이웃들에게는 비추천하지만, 사용자에게는 추천할만합니다.
따라서 각 사용자의 평점 bias를 취해서 추천결과를 계산하는 것이 더 좋은 추천 성능을 보인다고 판단할 수 있습니다.
(+) 만약 (1)식을 (1-2)식으로 바꾼다면 추천 결과를 어떻게 계산하나요?

기존(1) 식의 우변 둘째항은 neighborhood-based algorithm으로 두 사용자 또는 아이템 간의 유사성을 계산하고,
모든 랭킹의 가중 평균을 취하여 사용자에 대한 예측을 생성합니다.
식(1-2)에서는 유사성을 계산하지 않고 가중 평균이 아닌 단순 산술 평균으로 계산합니다.
따라서 k=1/|U| 로 식을 수정해서 최근접 이웃의 산술 평균으로 계산할 수 있습니다.
reference:
https://github.com/kakao/recoteam/blob/master/programming_assignments/mini_reco/interview.md
'인공지능 AI > 추천시스템' 카테고리의 다른 글
| [AI/추천시스템/RecSys] 추천 시스템의 성능 평가방법 (1) | 2023.01.26 |
|---|---|
| [AI/추천시스템/RecSys] Transformer기반 추천시스템 모델, SASRec, SSE-PT, BERT4Rec (0) | 2023.01.25 |
| [AI/추천시스템/Recommender System] 순차적 추천(Sequential Recommendation) (0) | 2023.01.21 |
| [AI/추천시스템/Recommender System] FM: Factorization Machine (0) | 2023.01.20 |
| [NLP/추천시스템/Recommender System] RecBole 라이브러리 소개 (0) | 2023.01.12 |