
Dense passage retrieval for Open-Domain QA
2020 EMNLP 게재 논문으로
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih
Facebook AI, University of Washington, Princeton University에서 쓴 논문입니다.
Information Retrieval 정보 검색 분야 모델로 DPR,
dual-encoder 모델을 활용한 dense passage retrieval 제안하였습니다.
Open-domain QA task에서는 후보 context를 고르기 위한 passage retrieval 중요합니다.
기존에는 sparse vector model로 TF-IDF, BM25 등의 모델이 있습니다.
본 논문에서는 dual encoder로 적은 데이터셋으로도 학습이 가능하게 dense representation으로 임베딩을 학습합니다.
retrieval 작업의 성능을 높이는데 초점을 맞추었습니다.
QA system의 reading comprehension models는 두 단계로 작동하는 프레임워크:
(1) Retriever: 질문의 답을 가진 small subset of passages 를 고릅니다.
(2) Reader: correct answer를 identify하는 작업을 합니다.
Retrieval in open-domain QA
기존의 tf-idf 모델과 다르게,
본 논문에서 제안하는 dense한 retrieval 모델은 sparse representations를 보완해줄 수 있습니다.
그래서 task-specific representation에서 유연성을 높입니다.
이 논문에서 해결하고자 하는 문제는,
"Can we train a better dense embedding model using only pairs of questions and passages (or answers), without additional pretraining?"
추가적인 사전학습 없이 몇개의 질문과 답 만으로만 dense embedding 모델을 더 잘 학습할 수 있을까?
Dense Passage Retriever (DPR)

질문과 내용(답)을 인코더에 각각 넣어서 내적을 구함으로써
유사성을 구합니다.
Encoder
두 개의 BERT를 사용하여 [CLS] 출력값을 output으로 씁니다.
Inference
모든 내용(passage)를 인코더 EQ로 임베딩하고, FAISS를 사용해 인덱싱 작업을 합니다.
(FAISS: similarity search 와 dense vectors 클러스터링을 해주는 오픈소스 라이브러리)
이로써 Index를 통해 question이 주어졌을 때 가까운 top K passage 벡터를 빠르게 inference 할 수 있습니다.
Training
위의 수식(1)은 메타러닝 기법으로 dot-product 유사성을 구해줍니다.
이 논문에서 학습의 목표는
"create a vector space such that relevant pairs of questions and passages will have smaller distance."
유사한 Q-A 쌍은 더 가까운 거리에 있을테니, 그런 벡터를 만들어보자!

수식(2)는 관련이 있는 similar한 애들끼리는 거리를 가깝게, = positive pairs
관련 없는 애들끼리는 거리를 멀게 = negative pairs
임베딩하는 작업입니다.
하나의 positive 샘플과 n개의 negative 샘플로 학습을 진행합니다.
In-batch negatives
빠르고 효과적인 학습 방법으로, In-batch negatives을 제안합니다.
따로 positive, negative 샘플 지정 안 하고 batch 안에서 계산하는 방법입니다.
임베딩된 Q와 P가 있을때,
각각 (B*d) 사이즈의 행렬입니다.
이 둘을
S = QP^T
B*B 배치에서 계산합니다.
이 둘의 내적을 구해서
대각 원소를 positive pair, 그 나머지를 nagative pair로 계산합니다.
실험은 두 가지에 대해 진행합니다.
첫째는 Retrieval을 얼마나 잘하는지
둘째는 Retrieval한 task에 대해 QA를 얼마나 잘하는지!
Experiments: Passage Retrieval

DPR과 BM25를 합친 모델에 대해서도 실험을 진행했습니다.

5.2 Ablation Study on Model Training
In-batch negative training

기존에 이미 존재하는 배치를 nagative example로 재사용함으로써 효과적으로 in-batch negative 학습을 합니다.
Experiments: Question Answering
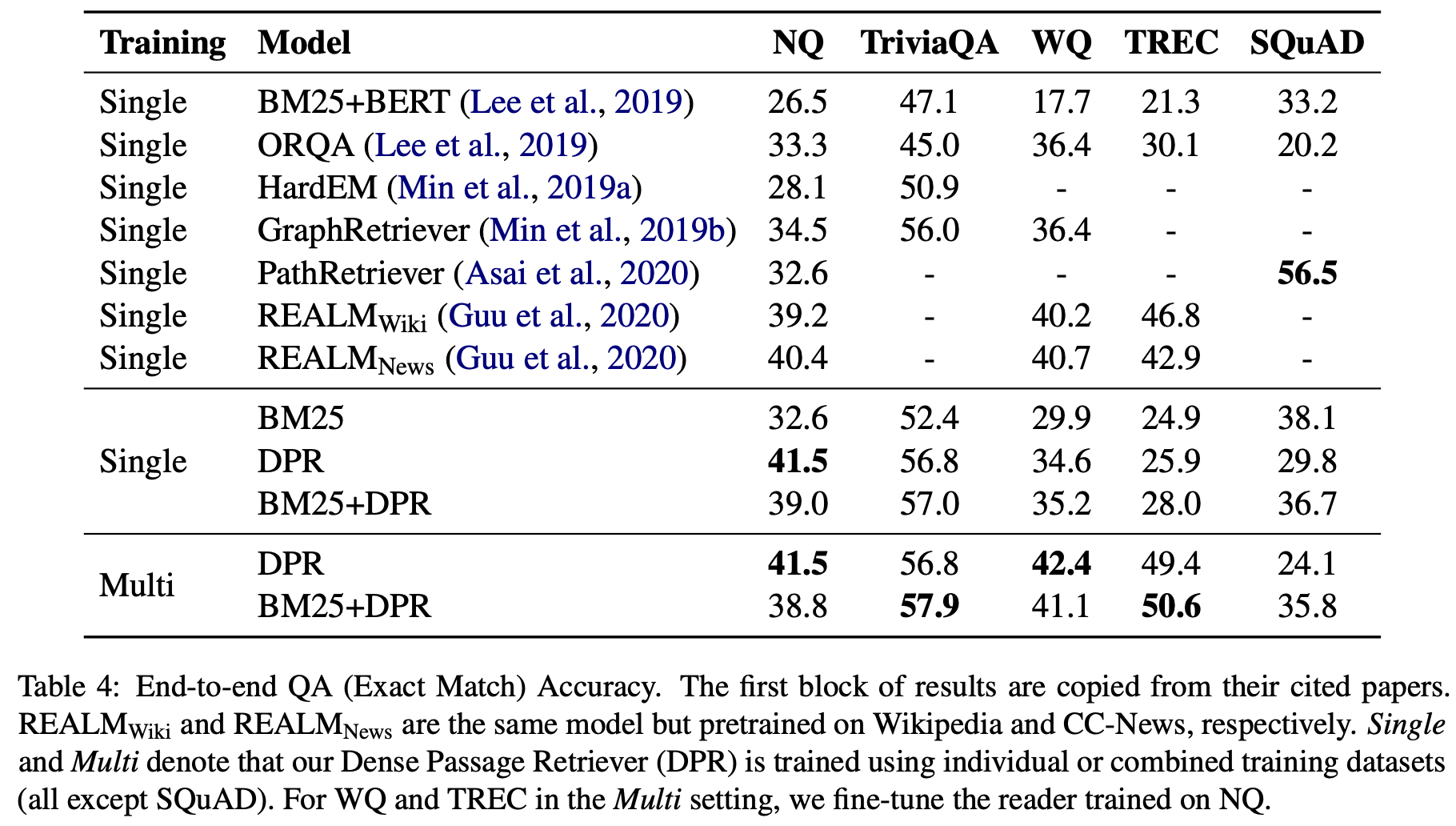
두 실험 모두 BM25보다 높은 성능이 보이고 있음을 알 수 있습니다.