
AAAI 2020 https://arxiv.org/pdf/1908.11007.pdf
Introduction
저자는 few-shot relation learning의 문제를 소개하고 이 작업에 대한 기존 방법의 한계에 대해 논의합니다.
그래서 해결책으로 신경 스노우볼 모델을 제안하고 main contributions를 개략적으로 설명합니다.

Related Work
few-shot learning, relation extraction, and entity linking에 관련연구들,,
저자는 Neural Snowball model을 기존 접근 방식과 비교하고 그 장점을 강조합니다.
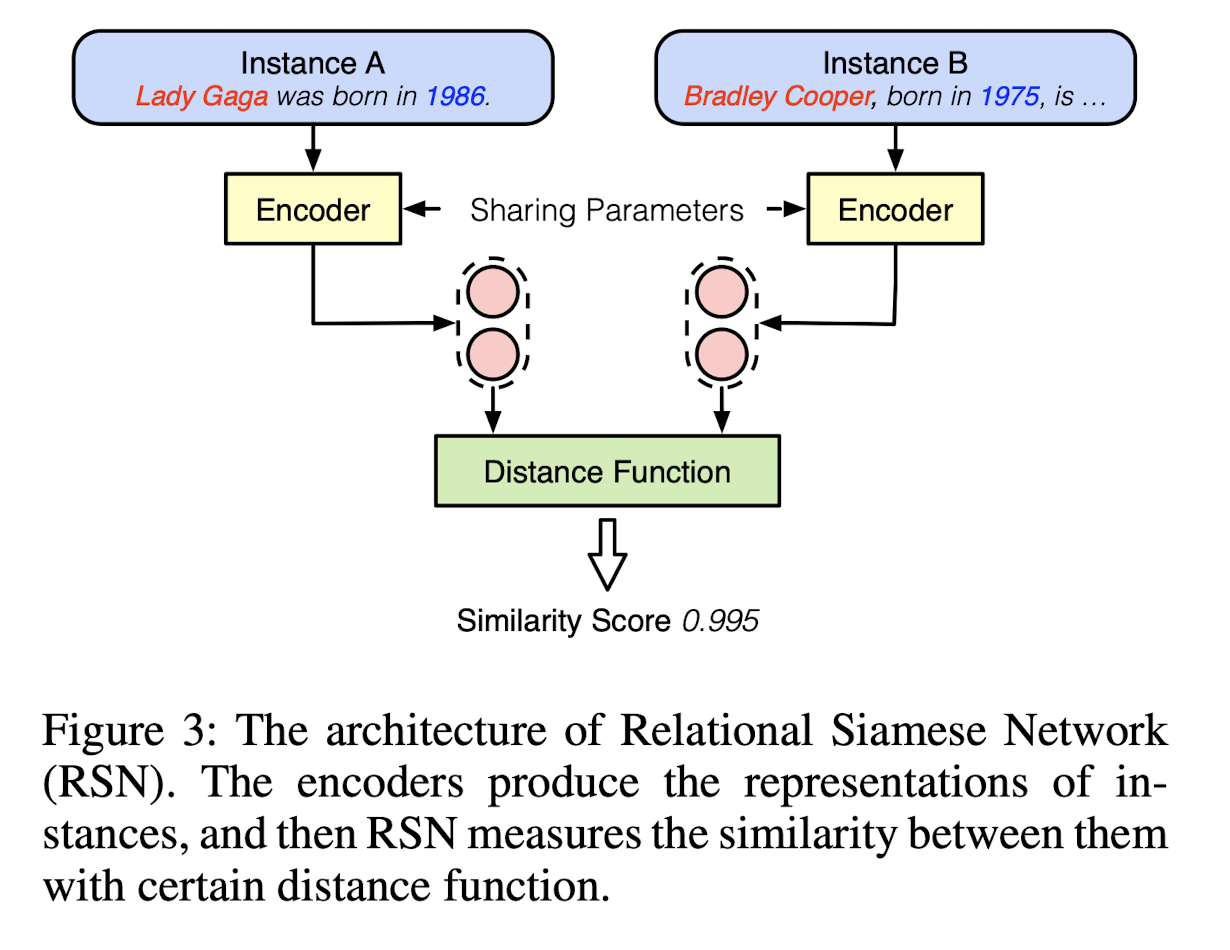
해당 논문은 RSNs(Relational Siamese Networks)를 채택해서 사용합니다.

Method
BERT 기반 인코더를 소개하고 엔티티 쌍의 컨텍스트 임베딩(contextual embeddings of entity pairs)을 얻는 데 사용되는 방법을 설명하는 것으로 시작합니다.
그런 다음 완전히 연결된 레이어의 순서(sequence of fully connected layers)와 관계 점수를 생성하는 데 사용되는 집계 함수(aggregation function used to produce a relation score)에 대해 논의합니다.
the Neural Snowball method
시드 인스턴스의 초기 집합을 사용하여 대상 관계에 속할 가능성이 있는 추가 인스턴스를 식별합니다
전체적인 프로세스는 수동으로 주석이 달린 대상 관계의 인스턴스인 시드 인스턴스 집합으로 시작합니다.
그런 다음 모델은 이러한 시드 인스턴스를 사용하여 주석이 없는 텍스트의 더 큰 말뭉치에서 후보 인스턴스 세트를 추출합니다.
후보 인스턴스는 일반적으로 시드 인스턴스와 유사한 언어 및 의미 속성을 가진 인스턴스를 캡처할 가능성이 있는 패턴 매칭 또는 기타 휴리스틱을 사용하여 식별됩니다.
다음으로, 모델은 인스턴스가 시드 인스턴스와 얼마나 유사한지 측정하는 유사성 함수(similarity scores)를 사용하여 각 후보 인스턴스의 점수를 매깁니다.
유사성 점수가 가장 높은 인스턴스는 시드 인스턴스 집합에 추가되고 프로세스가 반복됩니다. 이 반복 과정은 작은 씨앗에서 시작하여 더 많은 인스턴스가 추가됨에 따라 커지기 때문에 스노우볼 과정이라고 불린다.

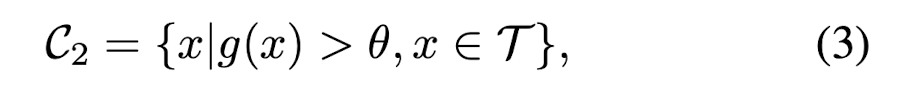
스노우볼 프로세스는 최대 반복 횟수 또는 최대 인스턴스 수와 같은 중지 기준이 충족될 때까지 계속됩니다.
결과적인 인스턴스 세트는 관계 추출 모델을 훈련하는 데 사용될 수 있습니다.
보다 신뢰할 수 있는 인스턴스를 반복적으로 선택함으로써 스노우볼 프로세스는 특히 훈련에 사용할 수 있는 레이블이 지정된 인스턴스가 몇 개밖에 없는 경우 관계 추출 모델의 성능을 향상시키는 데 도움이 될 수 있습니다.
결합 쌍둥이 또는 결합쌍생아(結合 雙 - , 영어: conjoined twins) 또는 때때로 시암/샴 쌍둥이(영어: Siamese twins)는 몸의 일부가 붙은 채로 태어난 쌍둥이를 말한다.
기존 RSNs과 Snowball의 차이:
RSNs(Relational Siamese Networks (RSNs) method)
기존 관계형 샴 네트워크(RSN) 방법은 관계 추출의 퓨샷 학습을 위해 설계되었으며, 여기서 작업은 문장에서 엔티티 쌍 간의 관계를 식별하는 것입니다.
RSNs 방법은 엔티티와 그 컨텍스트 쌍을 인코딩하는 방법을 학습한 다음 유사성 측정을 사용하여 이들 사이의 관계를 예측하는 샴 신경망입니다. 이와는 대조적으로, Snowball Method는 RSNs 방법을 기반으로 하며 소수의 인스턴스만으로 새로운 관계를 추출하는 작업으로 확장합니다. RSN을 사전 훈련된 인코더로 사용하여 레이블이 지정되지 않은 말뭉치에서 새로운 관계에 대한 신뢰할 수 있는 인스턴스를 반복적으로 선택함으로써 이를 달성한다.
신경 스노우볼의 스노우볼 프로세스는 관계에 대해 알려진 현재 인스턴스 세트와의 유사성을 기반으로 새로운 인스턴스를 반복적으로 선택한 다음 확장된 인스턴스 세트에서 RSNs 모델을 재학습하는 것을 포함합니다.
반복 선택함으로써 선택된 인스턴스의 품질을 점진적으로 향상시키고 노이즈가 많은 데이터의 영향을 줄여 관계의 새로운 인스턴스에 대한 더 나은 일반화로 이어지도록 설계되었습니다.
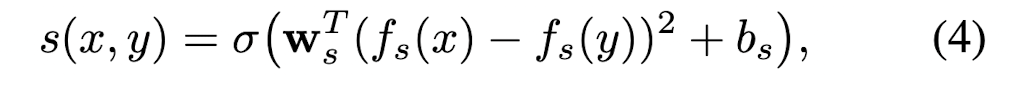
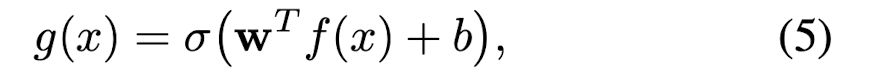
새로운 관계를 계속 추출해서 학습하면서 필연적으로 노이즈와 bias 문제를 피할 수 없습니다.
classifier의 w와 b로 최적화를 계속 진행하고, Sb는 positive batch, Tb는 negative batch로 손실함수는 다음과 같이 정의합니다.
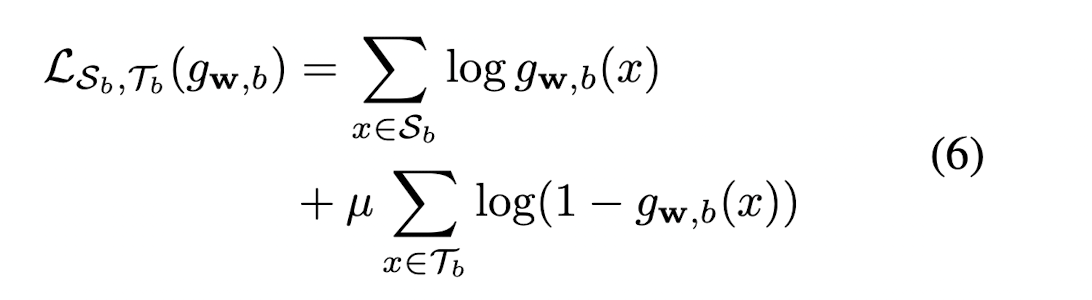
Fine-tuning the Classifier

positive sample과 negative sample을 각각 동일한 크기의 배치로 지정할 수도 있지만,
실제 관계 데이터셋에서의 인스턴스 수는 상당히 차이가 나기 때문에, negative sample에 더 작은 가중치의 loss를 부여했습니다.
Neural Encoders
이 논문에서는 인코더로 CNN과 BERT를 사용했습니다.
BERT인코더는 관계추출 작업에 맞게 엔티티 시퀀스의 앞뒤로 스페셜 마킹을 지정했습니다. (MTB 작업을 차용한 것 같습니다.)
Experiments
Neural Snowball model 실험의 experimental setup
사용된 데이터 세트, 실험 프로토콜 및 사용된 성능 메트릭:
FewRel(Han et al. 2018) 데이터셋을 사용했고, 100개의 관계 70,000개의 인스턴스를 가지는 위키백과 추출 데이터입니다.
스노우볼 방법을 위해서는 unlabeled 코퍼스(엔티티 태깅이 완료된)를 사용했는데, 899,996개의 인스턴스와 464,218개의 엔티티쌍을 가지고 있습니다.
자세한 파라미터 세팅은 grid searching으로 결정하고, classifier의 threshold는 0.9로 설정했습니다.
각 input query instance의 관계분류 확률을 최종결과로 냅니다.
fine-tuning에서 스노볼모델 classifier의 threshold는 0.5, 기존 RSNs는 0.7로 잡았다고 합니다.
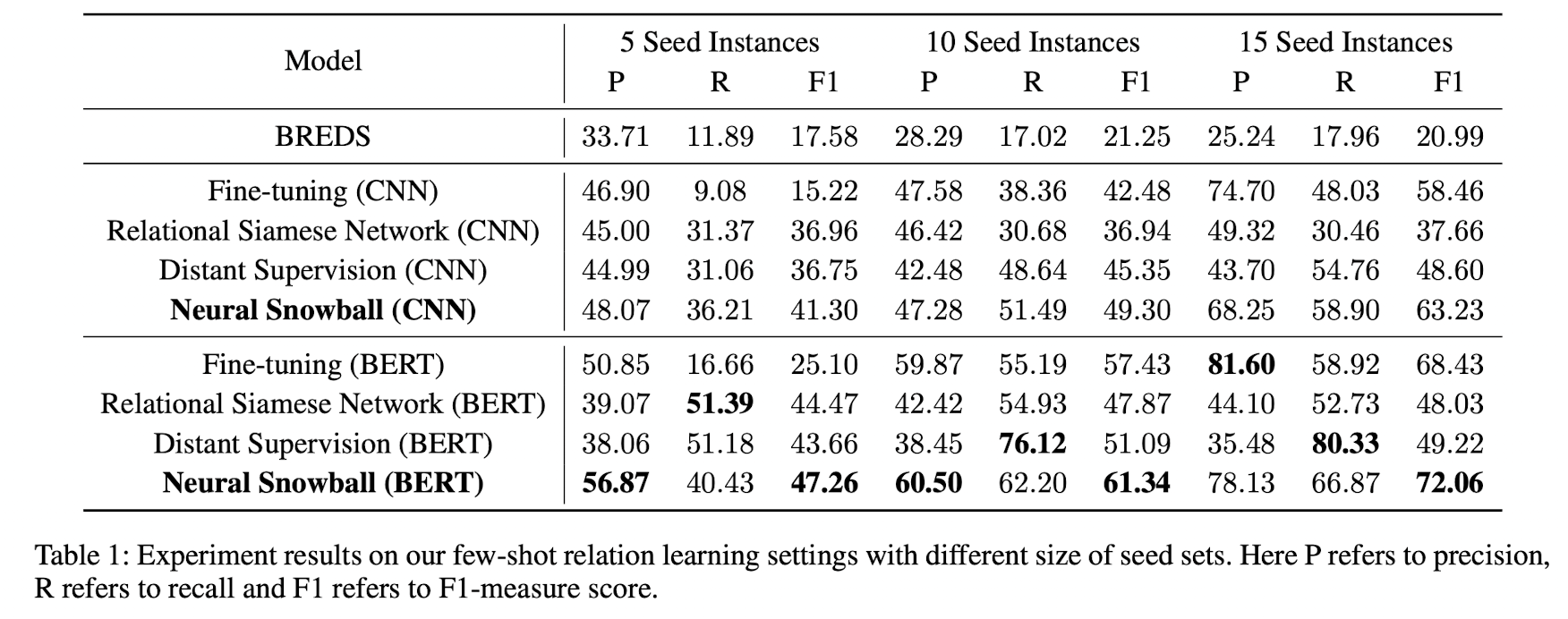
Precision뿐 아니라 Recall값도 높은 것으로 봐서, 새로운 학습 instance를 추출하는 것 뿐 아니라 새로운 관계 값과 인스턴스과 패턴매칭 또한 잘한다는 것을 확인할 수 있습니다.
기존 RSNs과 스노볼 프로세스 실험 비교
기존 RSNs 실험:
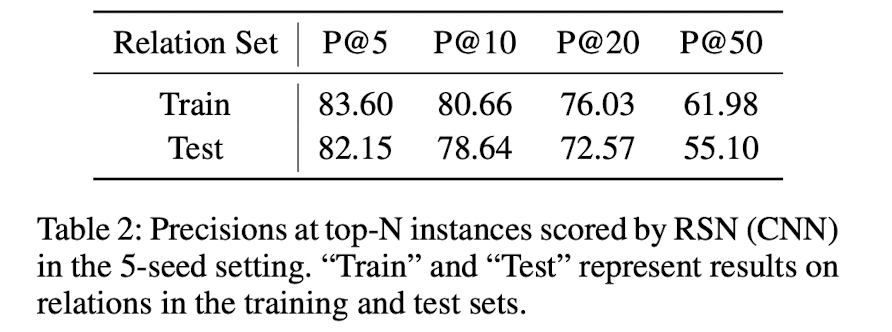
실험 방법은 랜덤한 관계값 하나, 그리고 5개의 인스턴스를 두고
나머지 데이터를 모두 query 인스턴스로 둡니다.
그리고 각 쿼리에 대해 메소드의 점수를 각각 매기고 top-N 인스턴스에 대한 precision을 매깁니다.(P@N)
굉장히 작은 양의 인스턴스만 주어진다는 것을 감안하면 5개의 인스턴스에 대한 82.15% precision은 상당히 높다고 볼 수 있습니다.
테스트 셋에서도 마찬가지로 비견되게 높은 점수가 나왔다는 것은 RSNs의 효율성을 확인할 수 있습니다.
스노우볼 실험:
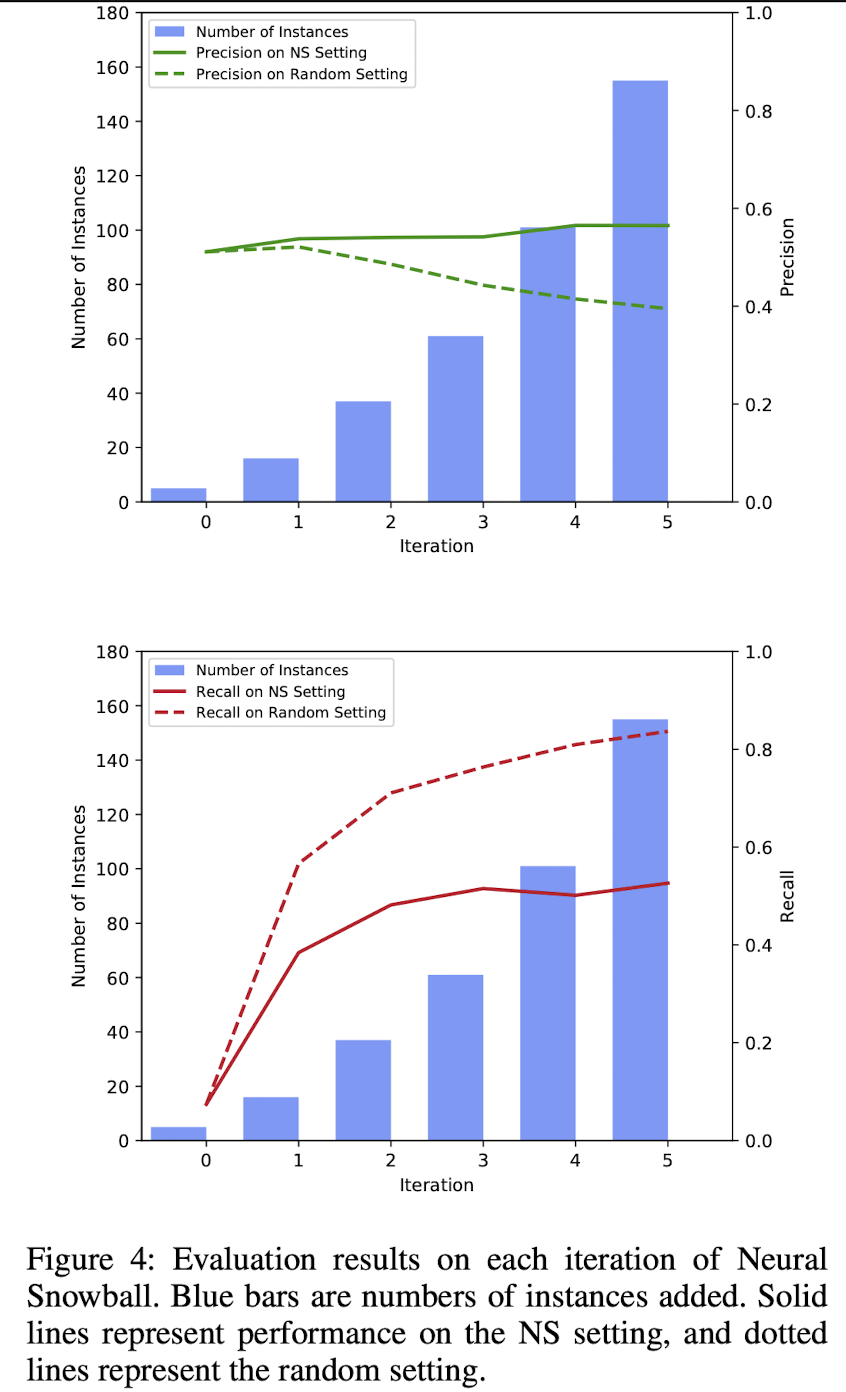
두 가지 설정값:
1. NS Setting: 스노우볼이 선택하는 인스턴스들에 fine-tune
2. Random Setting: 임의의 관계값 'Chairperson'에 대해 랜덤으로 선택되는 인스턴스들에 fine-tune
인스턴스가 커질수록 recall은 확 상승하고, precision은 조금 상승한 것을 보아서
데이터가 많을 수록 패턴매칭이 더 잘되고 성능은 조금 희생된다는 것을 알 수 있습니다
Precision은 랜덤세팅보다 스노우볼이 성능이 훨씬 높아지는 것을 확인 할 수 있지만,
Recall은 그에 못 미쳐서, 새로운 패턴에서 잘 적응을 못하는 한계를 살필 수 있습니다. (Stucks in the "comfort zone" and fails to jump out of the zone to discover patterns with more diversity.)
이에 대해 이를 극복하는 것이 미래임무라고 Conclusionand Future Work에 지적했습니다.