

구글이 소개한 자연어처리 언어모델 BERT를 간단하고 쉽게 구조를 설명해보았습니다.
LSTM vs Transformer
Transformer는 기존 RNN과 LSTM 문제를 해결하기 위해 등장하였다.
LSTM은 학습이 너무 느렸고, bidirectional하지 못하다는 단점이 있다.
하지만 Transformer는 학습이 빠르고 simultaneously하게 deeply bidirectional하다.
트랜스포머 모델은
encoder과 decoder로 구조가 이루어져있고
예를 들어, 영어->한국어로 번역작업을 한다면
encoder는 “My dog is called Henry.”라는 문장 단어들을 simultaneous하게 받아서
각 단어들의 임베딩을 simultaneously하게 작업한다.
decoder는 이런 임베딩들을 encoder로부터 받아서 한국어로 바꾸는 작업을 한다.
그리고 문장의 끝이 다다를때까지 하나씩 단어들을 번역한다.
encoder:”What is English? What is context?”
decoder:”How to map English words to Korean words?”
이렇게 language에 대해 이해하는 관점이 다르다.
BERT(Bidirectional Encoder Representation from Transformers)
그리고 openGPT 구조를 가져와서 BERT를 완성한다.
openGPT의 단점들을 해결하러 BERT는 이러한 작업들을 한다.
1. Neural Machine Translation
2. Question Anwsering
3. Sentiment Analysis
4. Text summarization
...등등
모두 language 이해가 필요한 작업들이다.
그래서 BERT는 두가지 흐름으로 이를 해결한다. (즉, BERT학습)
1. Pretrain BERT해서 language 이해 “I know language”
2. Fine tune BERT해서 구체적 작업을 배운다. “How do I solve this task?”
Pretraining BERT-“What is Language?”
두가지 unsupervised learning(비지도 학습)을 진행한다.
두 작업은 simultaneously하게 진행된다.
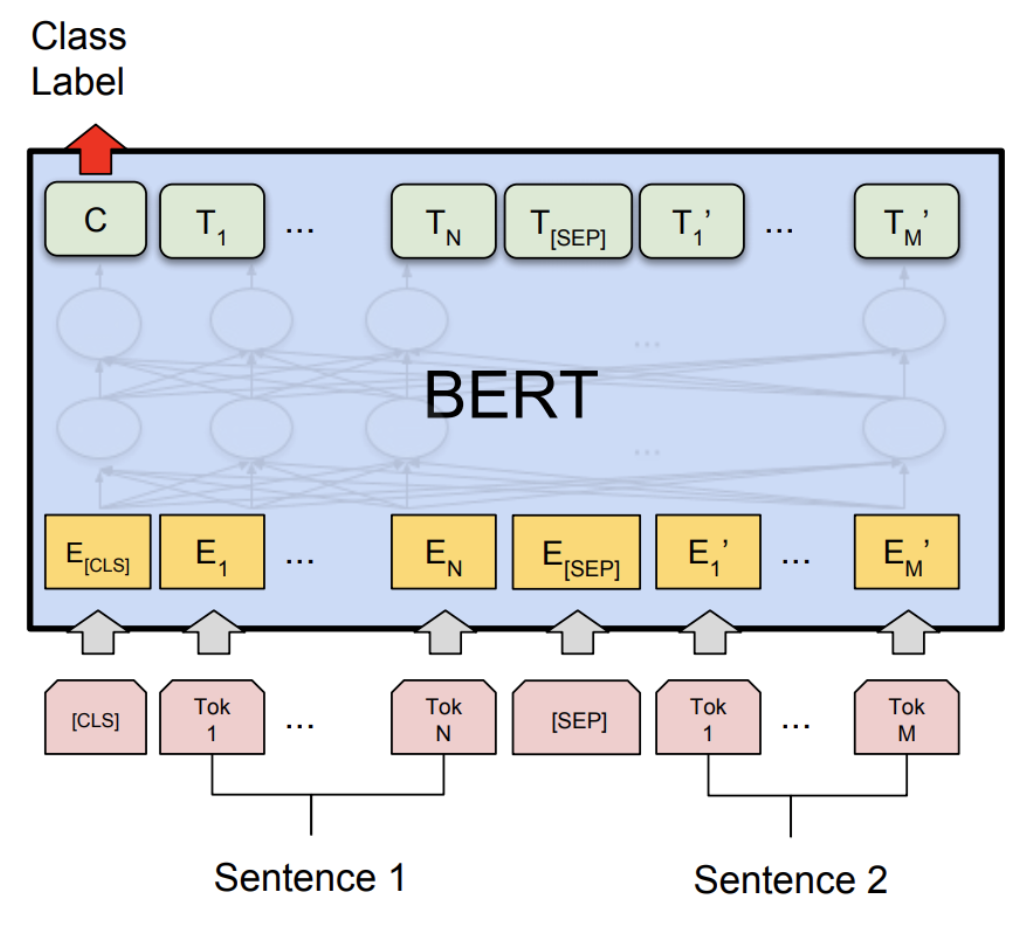
1. Masked Language Model(MLM)
랜덤 문장들을 마스킹해서 토큰화한다. 빈칸채우기 작업 같은 것이다.
그림의 핑크색들이다. 각 네모는 단어토큰들이다.
노란색 토큰들로 임베딩되는 것.
그 위의 초록색 T들은 word vector들로 MLM작업이 완료된 output애들이다. MLM input개수와 개수가 같다.
2. Next Sentence Prediction(NSP)
두 문장을 가져와서 a문장 다음에 b문장인지 판별한다. binary classification 작업 같은 것이다.
이 작업은 BERT가 많은 문장들의 문맥을 이해하는 데 도움이 된다.
그림의 초록색 토큰 C는 NSP의 binary output이다. 0이면 다음문장이 아니라는 것, 1이면 다음문장이라는 것.
이 두 작업을 거치면 BERT는 language 이해도가 높아진다.
Fine tuning BERT-“how do I use language for a specific NLP task?”
Question Anwsering
network의 fully connected output layer들을 대체해서 새로운 output layer들을 둔다.
이는 우리가 원하는 anwser output을 question으로부터 도출한다.
그리고 Q&A dataset을 이용해서 supervised task(지도 학습)을 진행한다.
output 파라미터만 이용되므로 속도는 빠르다.
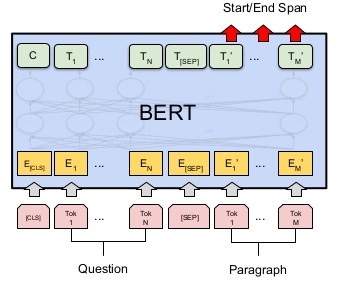
그림으로 다시 이해해보자. finetuning은 input output layer를 수정하는 작업이다.
question과 paragraph(answer포함)을 input으로 넣어
output은 start/end span(answer을 캡슐화)으로 한다. 텍스트와 같은 span
Pre-training 의 Embedding(임베딩)작업

Pretraining의 임베딩 작업을 자세히 살펴보자.
그림에서 순서대로
1. WordPieces Embeddings(Token Embeddings):
30K 단어들이 있는 WordPieces 임베딩을 사용한다.
2. Sentence Embeddings(Segment Embeddings):
문장으로 임베딩된 애들의 벡터들
3. Position Embeddings:
그 문장들의 인덱스를 붙인 벡터들
이 3가지 벡터들을 합하면 빨간색 네모들인 Input Vector들이 완성된다.
아래 그림에선 노란색 네모들이 완성되는 것이다.
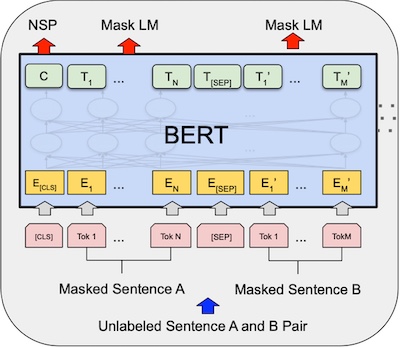
FineTuning_modifying layer (자세히 재설명)
이제 Output을 보자. (위에 초록색 아이들을 보면 된다.)
사전에 얘기했든 NSP와 MaskedLM을 마친 단어벡터들이 도착했다. (Pretraining을 마친 아이들)
(모든 word vector들은 같은 크기로 simultaneously하게 생성된다.)
wordpiece 사전에 있는 단어들과 fully connected하게 softmax layer(30000뉴런의)로 softmax함수를 실행한다.
그리고 one-hot 인코더로 비교해서 cross entropy loss로 학습한다.
loss는 mask된 단어들만 신경쓴다.
이렇게 BERT구조를 설명하였고, 이 구조의 과정들을 지나면
“Now I learned Language, and I can solve specific NLP tasks!”라고
BERT가 외친다.
Performance
구글의 논문에서는 SQuAD(Stanford Question&Anwser Dataset)을 사용하였는데,
30분 학습. single cloud TPU. 91% F1 score의 성능을 보여준다고 한다.
모델은
BERT Base (110M parameters)
BERT Large (340M parameters) 가 있다.
reference:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
youtube_CodeEmporium-BERT Neural Network-EXPLAINED!
'인공지능 AI' 카테고리의 다른 글
| [통계학]Confidence Interval(신뢰구간)/t-value/p-value (0) | 2021.11.20 |
|---|---|
| [인공지능/AI]Few-shot Learning in NLP(자연어처리) (0) | 2021.07.25 |
| [인공지능/AI] Hyperparameter Tuning (Optimization) 하이퍼파라미터 튜닝 (최적화) (0) | 2021.04.13 |
| [인공지능/AI] Cross Entropy 크로스 엔트로피 (0) | 2021.04.08 |
| [인공지능/딥러닝/AI] CNN 아키텍처기반의 MNIST 수행하기 (0) | 2020.08.26 |