
언어 모델은 추천 문제에 사용하기 좋습니다.
Seq2Seq 모델
번역 문제, QA 문제에 적용하며
긴 문장에 대해서는 성능이 떨어집니다.
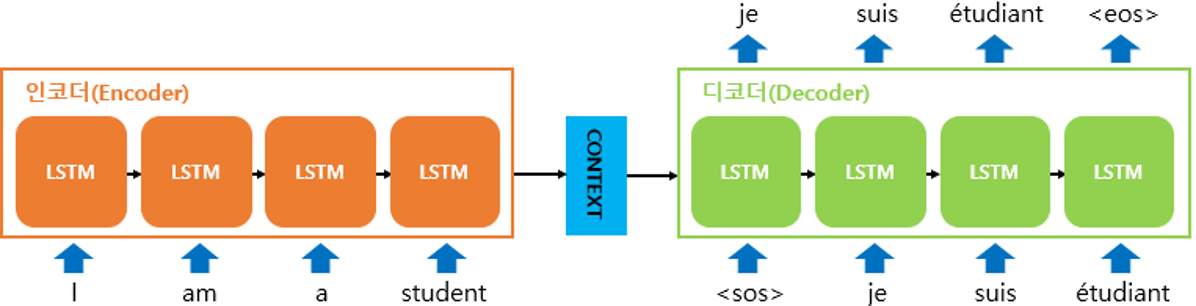
Attention 모델
Attention을 통해 어떤 노드를 얼마나 참조할지 가중치를 사용합니다.

이전 RNN 노드들을 다시 이용하여 최종 출력치를 결정합니다.
Transformer 모델

Attention 을 이용하여 encoding과 decoding을 진행합니다.
순서를 표시하기 위한 positional encoding을 함께 진행합니다.
Encoder: self-attention 사용
Decoder: 일반 attention 사용, masked self-attention 사용(순차적 입력 고려)
self-attention을 통해 단어 간 유사성을 파악할 수 있습니다.
그렇다면 이제 Transformer 기반의 추천시스템 모델들을 알아보겠습니다.
SASRec : Self-Attentive Sequential Recommendation

기존 Transformer 모델이 그렇듯이, RNN 계열의 모델의 단점을 보완하기 위해 제안되었습니다.
자연어처리 task에 SOTA 성능을 보이는 Transformer 모델을 추천시스템에 도입하였고, sequential data 특성상 모델에 큰 변형을 가하지 않았습니다.
기본 아이디어는 RNN 대신에 단방향 Self-Attention 모듈을 사용한 것입니다.
Self-attention은 RNN이나 Markov-chain 계열의 모델과 다르게 문장을 구성하는 단어들 간 의미적, 구조적 패턴을 잘 파악한다는 장점이 있습니다. 따라서 sequential data에 적합한 기계번역 모델에 굉장히 좋은 성능을 보여줍니다.
미래 행동을 보지 않고 현재 행동으로만 예측을 하는 것입니다.
positional embedding 으로 임베딩을 하고,
self-attention block을 지나서
최종 prediction layer에서 아이템 임베딩 벡터를 곱해 점수를 예측합니다.
여기에 개인별 성향을 보정해서 점수를 예측하는 것도 가능합니다.
복잡도:
공간복잡도는 FPMC 모델과 비슷합니다.
시간복잡도 n2d+nd2
SSE-PT: Sequential Recommendation Via Personalized Transformer
풀네임: Stochastic Shared Embeddings - Personalized Transformer
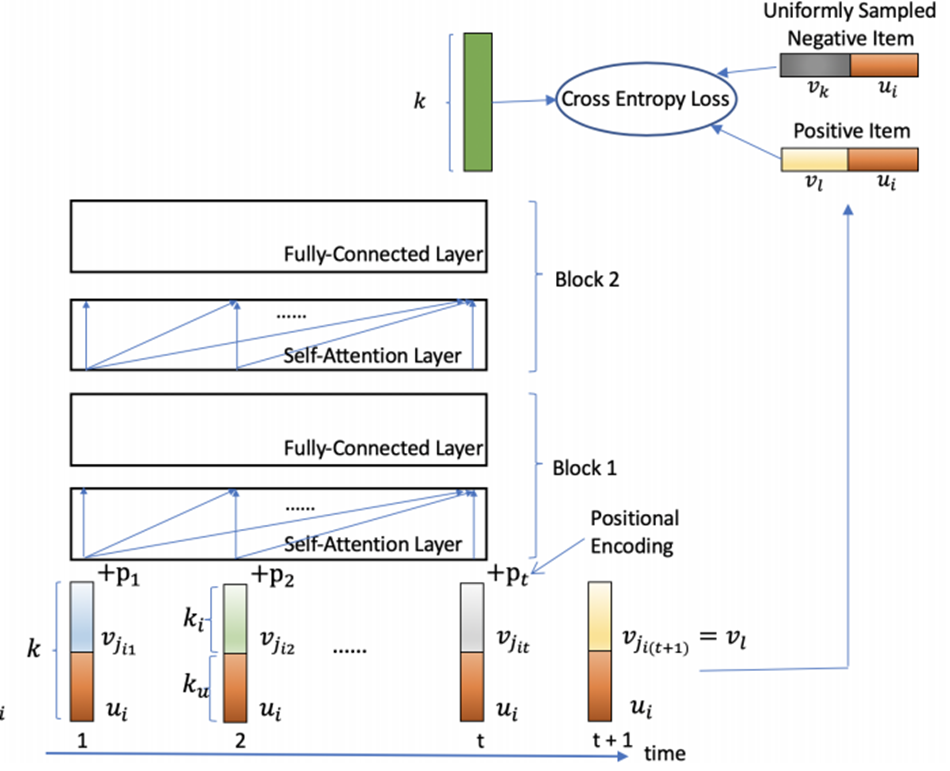
SASRec와 매우 유사하지만, 개인화된 추천을 강화하기 위해 사용자 벡터도 같이 임베딩에 적용하였습니다.
Transformer 기반으로 Stochastic Shared Embedding 방법을 적용하여서 개인화된 추천 시스템을 제안합니다.
SASRec과 마찬가지로
transformer layer에 단방향 self-attention 모듈을 사용하고,
prediction layer에 출력에 임베딩을 곱해서 최종 점수를 예측합니다.
그리고 SASRec과의 차이점은
overfitting 방지를 위해 stochastic shared embedding을 사용한 것입니다.
stochastic shared embedding은 정규화 방법으로 embedding layer에 적용합니다.

기존 layer normalization, dropout, weight decay 와 같은 기존 임베딩 방법들은 과적합 방지에 큰 도움이 되지 않았지만,
stochastic shared embedding 방법으로 과적합 방지하고 SASRec보다 성능이 5% 향상된 것을 확인했습니다.
BERT4Rec : Sequential Recommendation with Bidirectional Encoder Representations from Transformer
위의 두 모델은 단방향 self-attention 모듈을 사용했지만,
이 모델은 언어모델에서 가장 SOTA 성능을 보이는 BERT를 사용하여 양방향 self-attention을 사용하였습니다.
따라서 sequential data에서 중요한 순서가 사실 추천시스템에서 중요하지 않을 수 있다는 것이 이 모델의 키포인트입니다.
구매하는 순서가 꼭 중요하지 않다는 거죠.
BERT처럼 모델 훈련을 위해 masking 기반의 self-supervised 학습을 합니다.
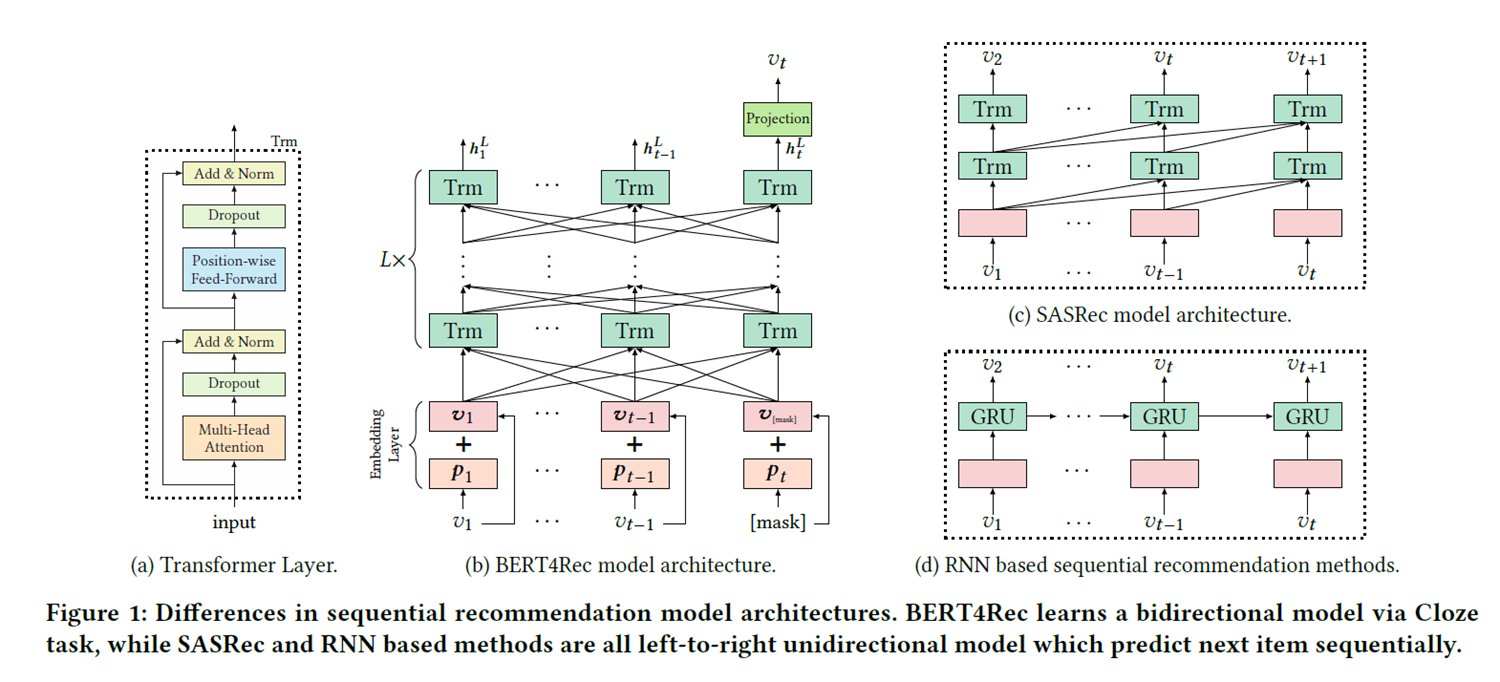
(a)는 트랜스포머 구조, (c)(d)는 비교대상인 SASRec와 RNN기반 sequential 추천모델, 그리고 (b)가 우리의 BERT4Rec 모델 아키텍처입니다.
이 구조 그림에서 중요한 것은 (b)에서 L개의 양방향 transformer layer 계층입니다.
기존 transformer layer가 그렇듯이 multi-head self attention과 position-wise feed-forward network로 구성됩니다.
이 모델은 feed-forward network의 활성화 함수로 GELU를 사용하였습니다.

모델 학습 방식: 랜덤 masking 방식

일정 비율로 아이템들을 랜덤하게 마스킹하고, 이 마스킹된 부분들을 추론하며 학습합니다. (기존의 BERT가 문장의 단어 토큰들을 추론하여 학습하는 것과 동일합니다.)
무작위로 k 개의 아이템을 마스킹할 때, (n k) 개의 샘플을 얻을 수 있으므로 훨씬 더 많은 샘플을 학습하는 것이 가능합니다.
그리고 학습과 다르게 테스트 시에는 사용자 행동 시퀀스의 마지막 토큰에 마스킹을 해서 아이템을 예측합니다.
성능평가:
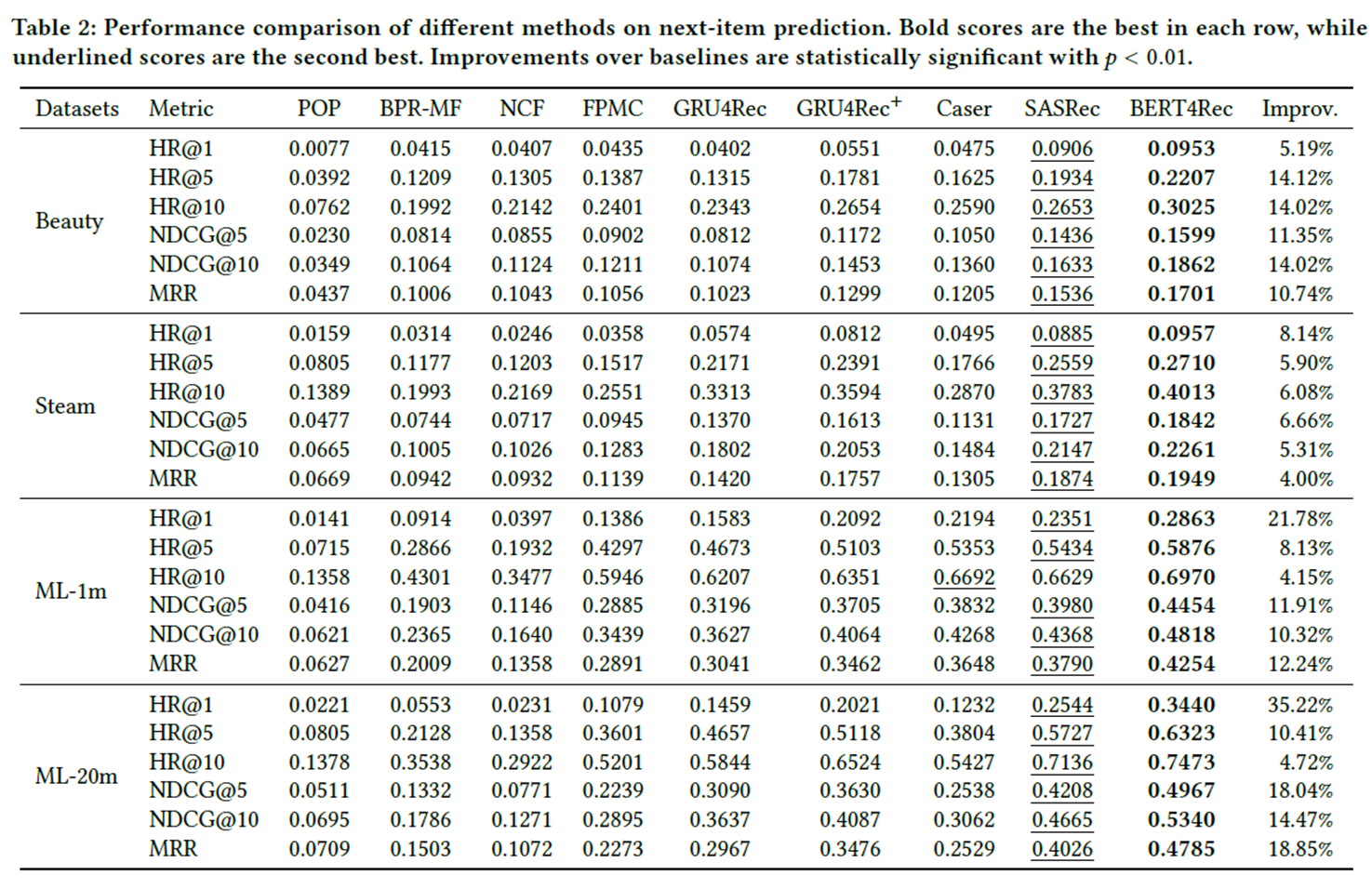
양방향 self-attention 모듈로 학습하여 성능이 뛰어나다는 점이 있지만,
마찬가지로 sequential data에 학습하였으므로 아이템 간 상호작용이 많은 task에 적합할 것으로 판단됩니다.
'인공지능 AI > 추천시스템' 카테고리의 다른 글
| [AI/추천시스템/RecSys] 추천 시스템의 성능 평가방법 (1) | 2023.01.26 |
|---|---|
| [AI/추천시스템/RecSys]Model-based, User-based 협업 필터링(Collaborative Filtering), 스포티파이(Spotify)의 RecSys (0) | 2023.01.24 |
| [AI/추천시스템/Recommender System] 순차적 추천(Sequential Recommendation) (0) | 2023.01.21 |
| [AI/추천시스템/Recommender System] FM: Factorization Machine (0) | 2023.01.20 |
| [NLP/추천시스템/Recommender System] RecBole 라이브러리 소개 (0) | 2023.01.12 |