
Zero-Shot Relation Extraction에 대한 새로운 접근 방식을 제안하는 논문입니다.
Introduction
저자는 Zero-Shot Relation Extraction이 두 엔티티 간 관계의 복잡한 의미론을 포착하지 못한다는 한계점을 지적합니다.
따라서 저자는 이 한계를 극복하기 위한 새로운 프레임워크, RCL(Relation Contrastive Learning for Zero-Shot Relation Extraction)을 소개합니다.
현재의 접근법이 pre-defined relations or supervised data에 의존하기 때문에 적용 가능성이 제한된다고 주장합니다. 저자는 contrastive learning을 활용하여 엔티티 쌍과 그 관계의 표현을 unsupervised으로 학습하는 새로운 방법인 관계 대조 학습(RCL)을 제안합니다.

기존 방법(baseline)은 표현 공간에서 두 관계에 속하는 데이터 포인트가 겹쳐 유사한 관계의 경우 잘못된 결과를 예측하는 경우가 많습니다.
이와 유사하게, 유사한 실체를 포함하는 관계 표현이 가깝고 기준선은 그렇지 않더라도 관계 표현으로 잘못 간주한다고 언급합니다.
이러한 과제를 해결하기 위해 저자들은 유사한 관계와 유사한 엔티티에서 파생된 관계 표현의 차이를 학습하기 위해 보이는 관계에 대한 인스턴스와이즈 대조 학습(Instance-CL)을 사용할 것을 제안합니다. 저자들은 Instance-CL이 동일한 클래스의 인스턴스를 통합하면서 다른 클래스의 인스턴스를 분리함으로써 표현 학습에서 놀라운 성공을 달성했다고 설명합니다.
RCL 프레임워크 개요
1. 한 쌍의 대상 엔티티를 포함하는 문장 배치가 문장 인코더에 입력되어 상황에 맞는 문장 임베딩을 생성한다.
2. relation augmentation layer은 관계 표현과 그에 상응하는 augmented view를 얻기 위해 설계된다.
3. RCL은 인스턴스 간의 차이를 학습하고 보이는 관계에 대한 contrastive loss and a relation classification loss을 공동으로 최적화하여 표현 공간에서 관계 간의 분리를 더 잘 달성한다.
4. 학습된 투영 함수 f를 사용하여 표현 공간에서 보이지 않는 관계 표현에 대해 전체 테스트 세트를 투영할 수 있으며 K-Means에 의한 보이지 않는 관계 표현에 대해 제로샷 예측이 수행된다.
이 연구의 주요 기여에는 유사한 관계와 엔티티 문제를 효과적으로 완화하는 제로샷 관계 추출을 위한 대조 학습 기반의 새로운 프레임워크 제안, 관계 증강에서 다양한 데이터 증강 전략을 탐구하고 잘 알려진 두 개의 데이터 세트에서 최첨단 성능을 달성하는 것이 포함된다.
Related Work
Zero-shot relation extraction, contrastive learning and unsupervised learning 관련 Related Work를 서술합니다.
저자는 특히 레이블이 지정된 데이터가 없는 경우 현재 접근 방식의 한계를 강조하고 RCL이 이러한 한계를 극복할 수 있다고 주장합니다.
Proposed Model
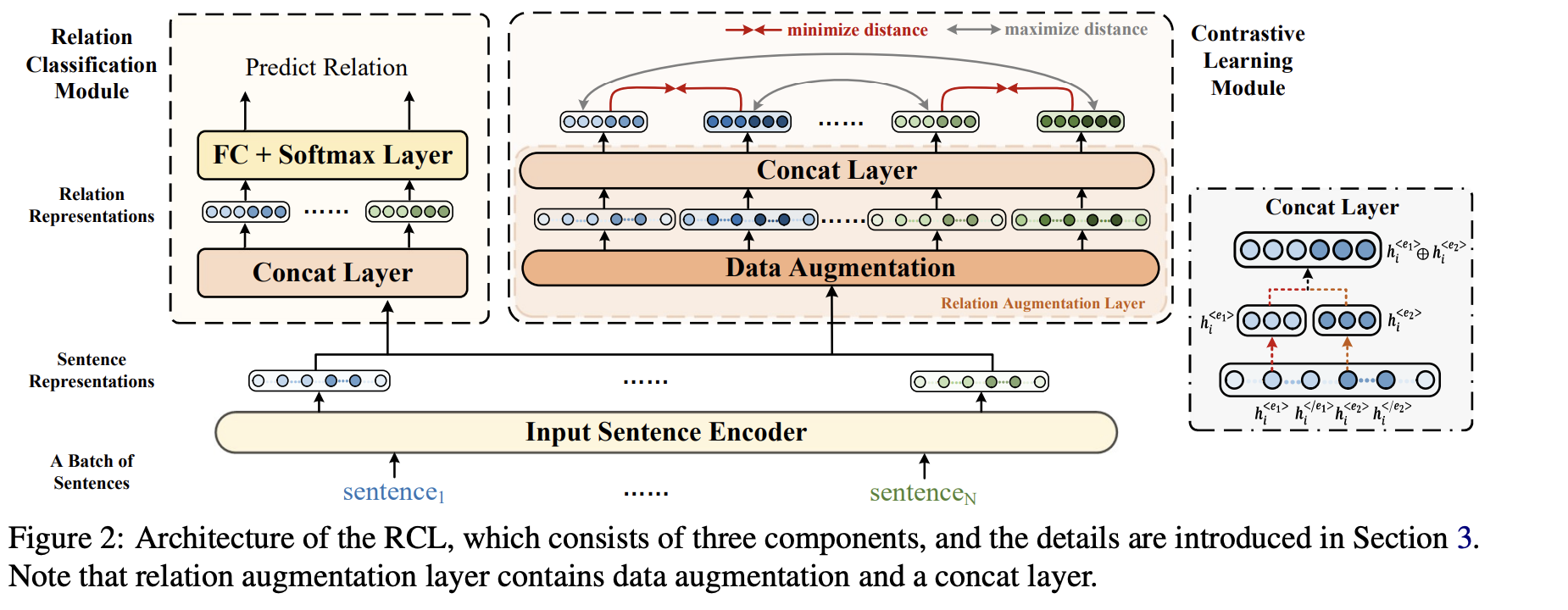
contrastive learning의 아이디어를 기반으로 하는 RCL 방법에 대한 자세한 설명을 제공합니다.
RCL은 먼저 한 쌍의 두 엔티티를 인코딩하고 관계 인코더를 통해 전달합니다.
그런 다음 모델은 양의 쌍(즉, 동일한 관계를 가진 쌍)의 표현이 음의 쌍(즉, 다른 관계를 가진 쌍)의 표현보다 서로 더 가깝도록 하기 위해 contrastive loss function을 사용합니다.
이 프로세스를 통해 모델은 레이블이 지정된 데이터 없이 엔티티 쌍과 그 관계의 유용한 표현을 학습할 수 있습니다.
Model Overview
RCL은 input sentence encoder, contrastive learning module, and relation classification module의 세 가지 주요 구성 요소로 구성됩니다. input sentence encoder는 문장 표현을 생성하며, 이는 contrastive learning module, and relation classification module에 모두 입력됩니다.
contrastive learning module은 contrastive instance learning을 수행하여 인스턴스 간의 차이를 학습합니다. 그것은 relation augmentation layer을 사용하여 관계 표현과 그에 상응하는 augmented view를 생성하는데, 이는 contrastive instance learning에 사용됩니다. 반면에, relation classification module은 concat layer에 의해 생성된 관계 표현을 활용하여 보이는 관계를 식별하고 관계 간의 더 나은 분리를 달성합니다.
RCL은 보이지 않는 관계에 대한 효과적인 표현을 학습하기 위해 contrastive learning module, and relation classification module을 모두 갖춘 다중 작업 학습 구조에서 훈련됩니다. 테스트 단계에서 보이지 않는 관계 표현은 입력 문장 인코더와 콘캣 레이어에 의해 얻은 다음 K-Means로 전송되어 보이지 않는 관계를 예측합니다.
Input Sentence Encoder
문장에서 각 토큰의 상황별 표현을 생성하는 것입니다.
문장에서 언급된 entitites가 입력 전에 이미 인식되었다고 가정합니다. 문맥에서 관계 특징을 추출하기 위해, 문장에서 언급된 각 엔티티의 시작과 끝을 표시하기 위해 4개의 특별한 토큰을 도입합니다. 입력 문장 인코더의 입력 토큰 시퀀스는 이러한 특수 토큰으로 문장을 보강하여 생성됩니다. 그런 다음 BERT 모델을 사용하여 문장 임베딩을 얻습니다. 결과 임베딩은 L x d의 모양을 가지며, 여기서 L은 문장의 길이이고 d는 BERT 모델의 숨겨진 차원입니다. (Matching the Blanks 프레임워크 그대로 쓴듯!)

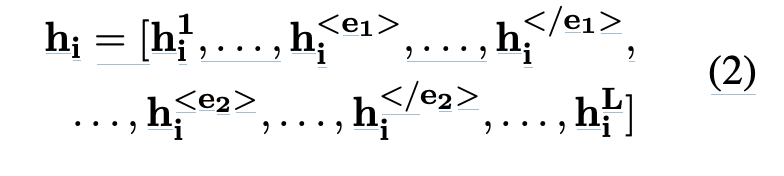
Contrastive Learning Module
RCL의 contrastive learning module은 관계를 더 잘 표현하기 위해 인스턴스 간의 차이를 학습하는 것을 목표로 합니다. 이 모듈은 변환 T를 적용하여 각 입력 문장의 임베딩에 대한 증강 뷰를 생성합니다. 그런 다음 이러한 augmented view와 원래 임베딩은 data augmentation 및 concat layer로 구성된 relation augmentation layer를 통과하여 고정 길이 관계 표현 ri와 해당 augmented view rˆi를 얻습니다.
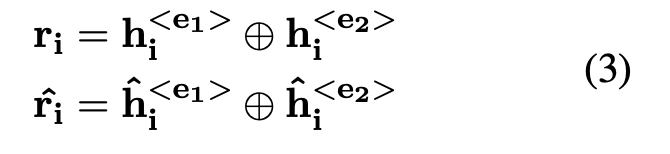
효과적인 표현을 최적화하기 위해, RCL은 contrastive objective를 사용하는데, 이 목표는 인스턴스의 다른 관계를 분산시키면서 인스턴스의 동일한 관계를 암시적으로 함께 가져옵니다. 구체적으로, RCL은 배치 내 cross-entropy objective with in-batch negatives를 취하고 양과 음의 관계 표현 쌍과 그 augmented view에 대해 학습합니다. 여기서 positive 쌍은 (ri, rˆi)로 구성되고 다른 N-1 augmented view는 negative 인스턴스입니다.
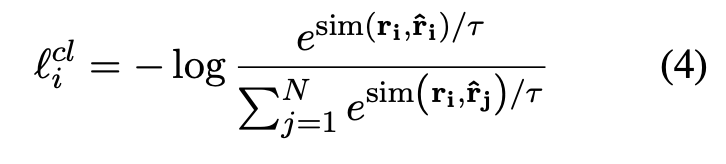
Data Augmentation Strategies
관계 표현의 의미를 깨지 않고 유사한 인스턴스 간의 의미적 차이를 증폭하기 위해 contrastive learning module에 사용되는 Data Augmentation Strategies 을 설명합니다. 저자들은 feature cutoff, random mask, dropout, composition of dropout and feature cutoff, and composition of dropout and random mask을 포함한 다섯 가지 다른 데이터 증강을 탐구합니다. feature cutoff는 입력 문장 인코더에 의해 생성된 문장 임베딩에서 일부 기능 차원을 무작위로 삭제하여 관계 인스턴스에 대한 최소의 의미적 영향을 도입합니다. random mask는 문장 임베딩의 요소를 특정 확률만큼 무작위로 떨어뜨리고 값을 0으로 설정합니다. dropout은 동일한 입력 문장을 BERT에 다시 입력하여 augmented view를 얻는 데 사용됩니다. 또한 데이터 증강의 구성에 대한 두 가지 전략, 즉 dropout과 feature cutoff의 구성과 dropout과 random mask의 구성을 탐구합니다. 이러한 전략의 실험 결과는 섹션 Qualitative Analysis에서 자세히 다룹니다.
Relation Classification Module
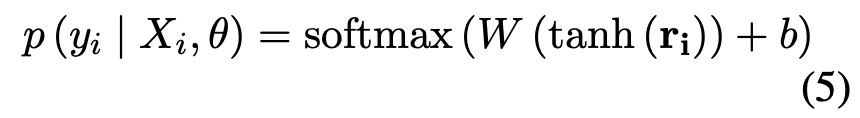

관계 분류 모듈은 보이는 관계를 식별하는 것을 목표로 합니다. 입력 문장 인코더에서 문장 임베딩 hi를 가져와서 concat layer를 사용하여 관계 표현 ri를 얻습니다. ri를 사용하여 모듈은 softmax layer를 적용하여 본 관계를 통해 i번째 샘플의 n차원 분류 확률 분포를 생성합니다. 여기서 n은 보이는 관계의 수를 나타내고 Ys는 보이는 관계의 집합을 나타냅니다. 모듈은 cross entropy를 사용하여 각 데이터 포인트 Xi에 대한 분류 손실을 계산합니다. 관계 표현 ri는 확률 분포 대신 제로샷 설정에서 보이지 않는 관계를 예측하는 데 사용된다는 점에 유의해야합니다.
Train and Test
RCL의 훈련 단계는 contrastive learning objective (LCL) and a relation classification objective (LRC)의 두 가지 목표를 포함하며, 두 목표의 균형을 맞추기 위해 hyper-parameter α와 joint loss function (Ljoint)로 결합된다. contrastive learning 목표는 미니 배치에서 other augmented relation representations 과 거리를 유지하면서 minimize the distance between relation representations and their augmented views 하는 것을 목표로 한다. 관계 분류 목표는 보이는 관계의 높은 예측 정확도를 가져오는 것을 목표로 한다. 테스트 단계에서 새로운 문장이 입력 문장 인코더와 Concat layer로 전송되어 보이지 않는 관계 표현을 생성하고, 보이지 않는 관계에 대한 예측은 K-Means에 의해 달성된다.

Experiments
두 가지 제로샷 관계 추출 작업인 FewRel과 TACRED에 대해 RCL을 평가하고 여러 기준 방법과 비교합니다.
결과는 특히 레이블이 지정된 데이터가 없는 경우 RCL이 두 작업 모두에서 기준선을 능가한다는 것을 보여줍니다.
또한 RCL 방법의 다양한 구성 요소의 중요성을 입증하기 위해 ablation studies를 수행합니다.
Datasets
SemEval2010 Task8은 관계 추출 작업에서 일반적으로 사용되는 데이터 세트로, 9개의 관계와 "Others" 관계를 포함한다. 데이터 세트에는 총 10,717개의 인스턴스가 포함되어 있으며 각 관계의 인스턴스 수가 동일하지 않습니다. 각 관계는 데이터 세트에 방향성이 있지만, 실험에서 9개 관계의 방향은 고려되지 않으며, "Others" 관계는 사용되지 않는다. 각 관계에 대해, 훈련 세트의 인스턴스는 각 관계의 전체 인스턴스를 얻기 위해 테스트 세트의 인스턴스와 결합된다.
FewRel은 위키피디아에 기반을 둔 공개 데이터 세트로, 각각 700개의 인스턴스를 가진 80가지 유형의 관계를 포함하고 있다. 퓨렐은 퓨샷 학습 설정에서 널리 사용되지만, 관계 레이블이 훈련 및 테스트 데이터 내에서 분리되어 있는 한 제로샷 학습에도 적합하다. 데이터 세트 통계는 부록 A에 나와 있다.
Evaluation Settings
Zero-shot Learning Settings
제로샷 학습 설정은 데이터 세트에서 보이지 않는 관계가 될 관계의 하위 집합과, 보이는 관계로 남아 있는 관계를 무작위로 선택하는 것을 포함한다. 그런 다음 훈련 데이터는 보이는 관계의 인스턴스로 제한되는 반면, 테스트 데이터는 보이지 않는 관계의 인스턴스만 포함한다. 실험을 5회 반복하고 평균 결과를 보고합니다. RCL 모델은 Transformers 패키지를 사용하여 구현되고 학습 속도가 5e-5인 Adam 옵티마이저로 훈련된다. 추가 구현 세부사항은 부록 B에서 확인할 수 있다.
Evaluation Metrics
B3(Bagga 및 Baldwin F1 점수)는 클러스터링 품질을 평가하는 데 사용되는 메트릭입니다. 그것은 precision and recall의 조화 평균을 측정하는데, 이것은 각각 각 문장을 클러스터에 넣고 모든 샘플을 단일 클래스로 클러스터링하는 정확도를 측정한다.
NMI(Normalized Mutual Information)는 예측 레이블과 실측 자료 간에 공유되는 상호 정보의 정도를 측정합니다. 값의 범위는 0부터 1까지이며, 1은 완전한 일치를 나타냅니다.
Adjusted Rand Index(ARI)는 두 클러스터링 결과 사이의 유사성을 측정하는 메트릭입니다. 값의 범위는 -1부터 1까지이며, 1은 완전 일치를 나타내고 0은 랜덤 군집을 나타냅니다.
Baseline
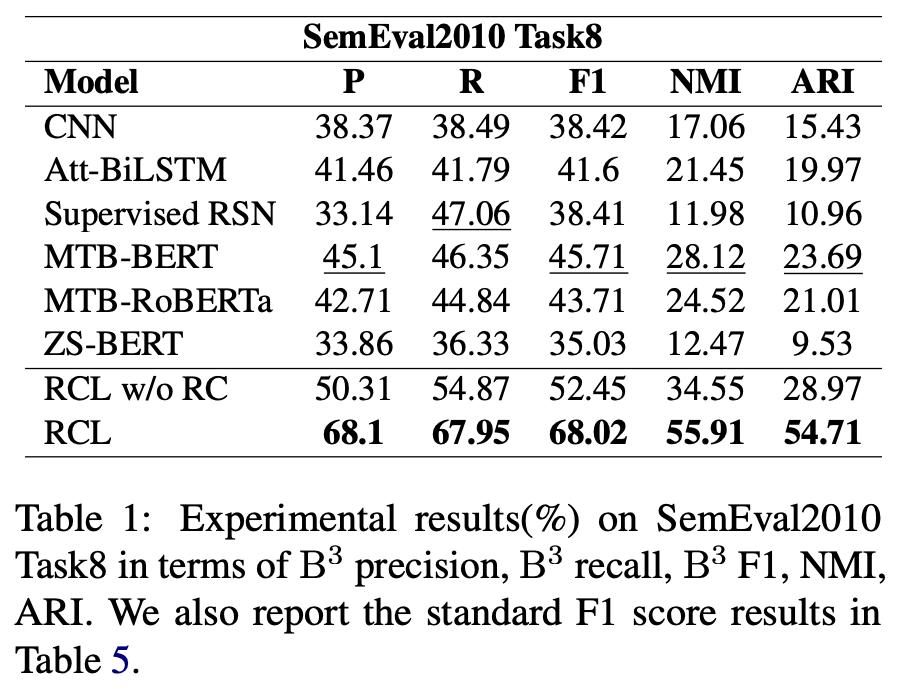
SemEval2010 Task8에 대한 이전 방법과 RCL을 비교한 결과는 표 1에 제시되어 있다. RCL은 F1, NMI 및 ARI의 상당한 개선으로 이전의 SOTA를 능가한다. 기준 모델의 성능이 좋지 않은 것은 데이터 세트의 관계, 클래스 불균형 및 데이터 세트가 변압기가 사전 훈련된 일반 도메인과 관련이 적기 때문이다. 그러나 RCL은 이러한 문제를 효과적으로 완화하고 사전 훈련 언어 모델의 일반적인 지식을 더 잘 활용한다.

FewRel
MTB-BERT 및 MTB RoBERTa는 RCL보다 성능이 우수하지만 여전히 낮은 반면, ZS-BERT는 외부 리소스에 의존하기 때문에 대부분의 경쟁 모델보다 성능이 떨어진다. RCL은 유사한 관계의 문제를 효과적으로 처리하고 외부 자원 없이도 잘 수행한다.
Ablation Study
이 논문은 효과를 검증하기 위해 RCL의 각 모듈에 대한 ablation study를 수행한다. 결과는 두 모듈(대조 학습 및 관계 분류)을 결합하면 SemEval2010 Task8 및 FewRel 데이터 세트 모두에서 성능이 눈에 띄게 향상될 수 있음을 보여준다.
구체적으로, RCL은 모든 평가 지표에서 기존 기준선을 능가하며, (대조 학습 없이) RCL w/or RC는 여전히 기존 기준선을 능가한다.
그러나 제안된 RCL은 RCL w/or RC를 크게 능가하여 두 모듈이 관계 표현 학습에서 상호 보완적임을 나타낸다.
FewRel에서 보이지 않는 관계의 수가 증가할 때, RCL w/or RC는 경쟁 방법보다 성능이 떨어져 두 모듈 모두 최종 모델 성능에 중요하다는 것을 보여준다.

Qualitative Analysis
Effect of Data Augmentations.
본 논문은 데이터 증가가 제안된 방법의 성능에 미치는 영향을 연구하기 위해 Qualitative Analysis을 수행한다. 6가지 다른 데이터 확대 전략이 고려되며, 그 결과는 dropout이 가장 효과적인 전략이며, random mask와 feature kickoff도 성능을 향상시킨다는 것을 보여준다. dropout과 random mask 및 dropout의 구성과 feature kickoff는 효과적인 것으로 나타났지만 dropout은 여전히 이들을 능가한다. 이 모델은 또한 데이터 증강 없이도 두 데이터 세트 모두에서 성능을 향상시켜 외부 리소스가 없는 대조 학습의 효과를 입증할 수 있다.
Effect of Number of Seen Relations.

이 섹션에서는 충분한 관계를 포함하는 FewRel 데이터 세트에 대한 보이는 관계 수의 영향을 분석한다. 이 실험은 보이지 않는 관계의 수를 10으로 고정한 상태에서 보이는 관계의 수를 10에서 70으로 변경합니다. 결과는 보이는 관계의 수가 증가함에 따라 RCL이 MTB-BERT를 지속적으로 능가한다는 것을 보여준다. 보이는 관계의 수가 10(부족)으로 설정된 경우에도 RCL은 90% F1 점수를 달성하여 제안된 접근 방식의 효과를 입증한다. 또한, RCL의 성능은 보이는 관계의 수가 불충분해질 때 MTB-BERT보다 더 매끄럽게 감소하여 접근 방식의 견고성을 나타낸다.
Capability under Few-shot Settings.
이 섹션에서는 퓨샷 설정에서 RCL의 기능을 평가한다. 실험은 각 보이지 않는 관계의 작은 부분의 문장을 테스트 데이터에서 훈련 데이터로 이동하여 수행된다. 결과는 RCL이 훈련 단계에서 더 많은 보이지 않는 관계 인스턴스를 사용하여 더 많은 F1 점수 향상을 달성한다는 것을 보여준다. 분수를 4%로 설정하면 RCL은 FewRel에서 90% F1 점수, SemEval 2010 Task8에서 80% F1 점수를 달성하여 퓨샷 학습 능력을 입증할 수 있다.
Visualization of Relation Representations.

이 논문은 보이는 관계에 대한 더 나은 관계 표현을 학습하는 데 있어 RCL의 효과를 입증하기 위해 관계 표현의 시각화를 제시한다. t-SNE 알고리듬은 관계 표현의 차원성을 2로 줄이기 위해 사용되며, SemEval2010 Task8에서 보이지 않는 관계로 4개의 관계가 무작위로 선택된다. 시각화 결과는 MTB-BERT의 데이터 포인트가 특히 유사한 관계나 엔티티를 가진 인스턴스의 경우 서로 다른 클러스터와 혼합되는 반면, RCL은 인스턴스와 보이는 관계 간의 차이를 학습하여 이러한 문제를 효과적으로 완화한다는 것을 보여준다. 시각화 결과는 RCL의 대조 손실 및 다중 작업 학습 구조의 효과에 대한 추가 증거를 제공한다. 또한 사례 연구가 부록에 제공됩니다.
Conclusion
RCL이 특히 레이블이 지정된 데이터가 부족하거나 사용할 수 없는 상황에서 제로샷 관계 추출을 위한 유망한 방법이라고 결론짓습니다.
또한 그 방법을 다른 자연어 처리 작업으로 확장하고 semi-supervised learning 환경에서 RCL의 사용을 탐구하는 것과 같은 향후 연구를 위한 몇 가지 방법을 제안합니다.
전반적으로 제로샷 관계 추출에서 RCL의 효과에 대한 설득력 있는 사례를 제공하며, 실험 결과가 이러한 주장을 뒷받침합니다.
요약하면, 본 논문은 제로샷 관계 추출을 위한 관계 대조 학습(RCL)이라는 새로운 프레임워크를 제안합니다. RCL의 목표는 유사한 관계와 유사한 실체라는 두 가지 유형의 유사한 문제를 해결하는 것입니다. 이를 달성하기 위해 RCL은 대조 학습을 사용하여 동일한 클래스의 인스턴스를 통합하고 다른 클래스의 인스턴스를 분리하여 효과적인 표현을 학습한다. 또한 대조적 인스턴스 학습의 의미론적 영향을 최소화하기 위해 관련 증강에서 다양한 데이터 증강 전략을 탐구한다.
제안된 모델은 입력 문장 인코더, 대조 학습 모듈 및 관계 분류 모듈의 세 가지 구성 요소로 구성된다. 훈련 단계에서 RCL은 다중 작업 학습 구조에서 두 가지 목표로 훈련된다. 테스트 단계에서 새로운 문장은 입력 문장 인코더와 콘캣 계층으로 전송되어 보이지 않는 관계 표현을 생성하고, 보이지 않는 관계에 대한 예측은 K-Means에 의해 달성된다. 실험 결과는 RCL이 잘 알려진 두 개의 데이터 세트에서 최첨단 방법에 비해 크게 향상되었음을 보여준다.
RCL은 관계 인스턴스의 증강 뷰를 생성하는 방법을 배우고 동일한 관계 인스턴스의 증강 뷰가 서로 다른 관계 인스턴스의 증강 뷰와 거리를 유지하면서 근접하도록 장려한다. RCL은 또한 보이는 관계를 예측하기 위해 관계 분류 모듈을 훈련시키고 K-평균 군집화를 사용하여 제로샷 예측을 생성한다. 제안된 방법은 SemEval2010 Task8 및 FewRel 데이터 세트 모두에서 기존 기준선을 능가하여 F1, NMI 및 ARI 메트릭에서 상당한 개선을 달성한다. RCL은 또한 유사한 문제를 완화하고 사전 훈련 언어 모델의 일반 지식을 더 잘 활용하는 데 효과적인 것으로 나타났다.
'인공지능 AI > 자연어처리' 카테고리의 다른 글
| [NLP/LLM] LLM 용어 정리 (0) | 2024.01.22 |
|---|---|
| [NLP] Adversarial Attacks on LLMs (LLMs 대한 적대적공격) (0) | 2023.11.24 |
| [NLP/RSNs/RE] Neural Snowball for Few-Shot Relation Learning (2) | 2023.02.22 |
| [논문리뷰/NLP/IR/NLG] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2023.02.03 |
| [논문리뷰/NLP/IR] Dense passage retrieval for Open-Domain QA (1) | 2023.02.02 |