
Adversarial Attacks on LLMs
https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/
Adversarial Attacks on LLMs
The use of large language models in the real world has strongly accelerated by the launch of ChatGPT. We (including my team at OpenAI, shoutout to them) have invested a lot of effort to build default safe behavior into the model during the alignment proces
lilianweng.github.io
LLM에 대한 적대적 공격에 대한 얘기가 재밌어보여서 가져와봤다.
보통 적대적 공격에 대한 연구들이 이미지 중심인데, 텍스트에서 어떻게 활용하나 궁금했다.
LLM을 공격하는 것은 본질적으로 특정 유형의 (안전하지 않은) 콘텐츠를 출력하도록 모델을 제어하는 것이다.
White-box vs Black-box
화이트박스 공격은 공격자가 모델 가중치, 아키텍처 및 학습 파이프라인에 대한 전체 액세스 권한을 가지고 있다고 가정하여 공격자가 기울기 신호를 얻을 수 있다고 가정한다. 공격자가 전체 학습 데이터에 액세스할 수 있다고 가정하지 않는다. 이는 오픈 소스 모델에서만 가능하다.
블랙박스 공격은 공격자가 입력을 제공하는 API와 유사한 서비스에만 액세스할 수 있다고 가정한다.(모델 정보 없이)
Token Manipulation
일련의 토큰이 포함된 텍스트 입력이 주어지면 동의어로 대체하는 것과 같은 간단한 토큰 연산을 적용하여 모델이 잘못된 예측을 하도록 트리거할 수 있다. 토큰 조작 기반 공격은 블랙박스 설정에서 작동한다. Python 프레임워크인 TextAttack(Morris 외. 2020)은 다양한 단어 및 토큰 조작 공격 방법을 구현하여 NLP 모델에 대한 적대적인 예제를 만들었고, 이 분야의 대부분의 연구는 분류 및 수반 예측을 실험했다.
Gradient based Attacks
경사도 기반 공격은 오픈 소스 LLM과 같은 화이트박스 설정에서만 작동한다.
적의 공격 목표는 거부해야 하는 요청에 직면했을 때에도 LLM이 긍정적인 응답을 출력하도록 트리거하는 것이다. 즉, 악의적인 요청이 주어지면 모델은 "예, 방법은 다음과 같습니다..."와 같이 응답할 수 있다. ㄷㄷ
Jailbreak Prompting
완화되었어야 하는 유해한 콘텐츠를 출력하도록 LLM을 악의적으로 트리거한다. 블랙박스 공격이므로 문구 조합은 휴리스틱 및 수동 탐색을 기반으로 한다.
Humans in the Loop Red-teaming
QuizBowl QA dataset QuizBowl QA 데이터세트를 실험하여 인간이 유사한 제퍼디 스타일의 문제를 작성하여 모델이 잘못된 예측을 하도록 속일 수 있는 적대적 작문 인터페이스를 설계했다.
각 단어는 단어 중요도(즉, 단어 제거 시 모델 예측 확률의 변화)에 따라 다른 색상으로 강조 표시된다. 단어 중요도는 단어 임베딩에 따른 모델의 기울기로 근사화된다.

Model Red-teaming
모델 기반 레드팀링의 주요 과제는 레드팀 모델을 학습시키기 위한 적절한 학습 신호를 구성할 수 있도록 공격이 성공한 시점을 판단하는 방법이다.
유해 콘텐츠를 탐지하는 완벽한 분류기를 구축하는 것은 불가능하며, 분류기 내에 편향성이나 결함이 있으면 편향된 공격으로 이어질 수 있다. 특히 RL 알고리즘은 분류기의 사소한 문제를 효과적인 공격 패턴으로 악용하기 쉬우며, 이는 결국 분류기에 대한 공격으로 이어질 수 있다. 또한 기존 분류기를 직접 사용하여 학습 데이터를 필터링하거나 모델 출력을 차단할 수 있기 때문에 기존 분류기에 대한 레드팀 공격의 이점이 미미하다고 주장하는 사람들도 있다.
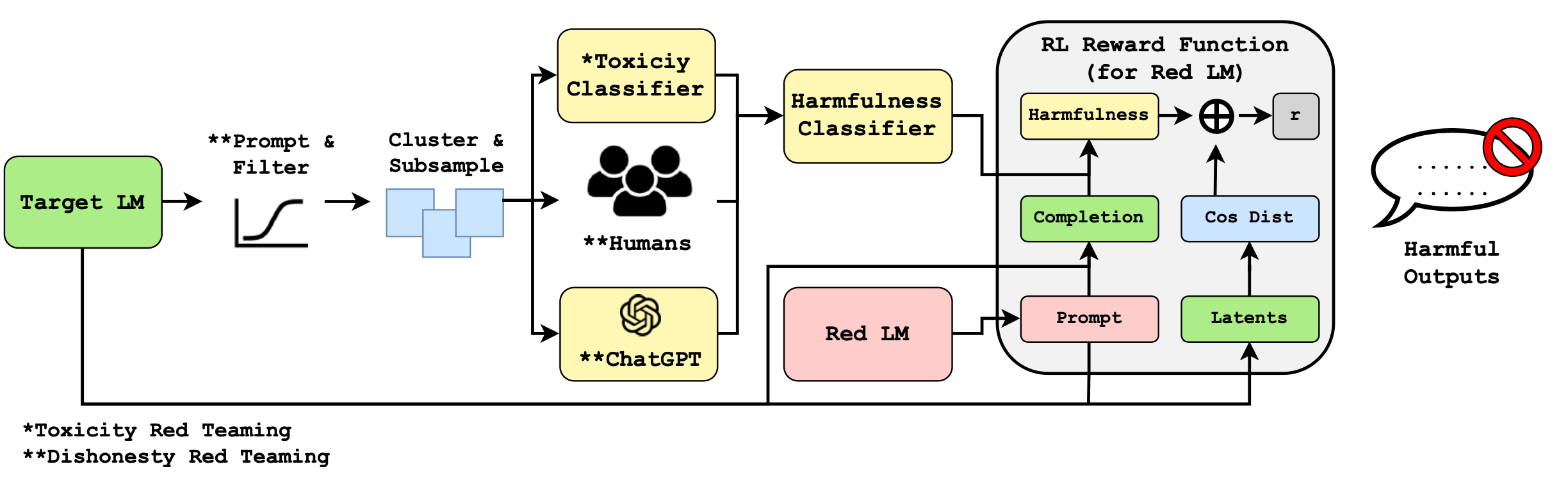
그렇다면 LLM 강건성을 어떻게 지키지?
적대적 공격으로부터 모델을 방어하는 간단하고 직관적인 방법 중 하나는 모델에 유해한 콘텐츠를 생성하지 말고 책임을 지도록 명시적으로 지시하는 것이다.
이 방법은 Jailbreak 공격의 성공률을 크게 낮출 수 있지만, 모델이 더 보수적으로 행동하거나(예: 창작물 작성) 일부 시나리오(예: 안전-비안전 분류)에서 지침을 잘못 해석하기 때문에 일반적인 모델 품질에 부작용을 초래할 수 있다.
적대적 공격의 위험을 완화하는 가장 일반적인 방법은 적대적 훈련이라고 하는 공격 샘플로 모델을 훈련하는 것이다.
이 방법은 가장 강력한 방어 수단으로 간주되지만 견고성과 모델 성능 간에 상충되는 결과를 초래한다.
2023년 Jain 등이 수행한 실험에서는 두 가지 적대적 훈련 설정을 테스트했습니다.
(1) 유해한 프롬프트에 대해 경사도 하강을 실행하고 "죄송합니다. 죄송합니다..."라는 응답과
(2) 훈련 단계당 거부 응답에 대해 하강 단계를 한 번 실행하고 적색팀 나쁜 응답에 대해 상승 단계를 실행.
(2)의 방법은 모델 생성 품질이 많이 저하되는 반면 공격 성공률의 하락폭은 작기 때문에 결국 쓸모가 없게 된다.
화이트박스 공격은 종종 무의미한 공격 프롬프트로 이어지므로 난해성을 검사하여 탐지할 수 있다. 물론 화이트박스 공격은 UAT의 변형인 UAT-LM (Universal Adversarial Trigger with Language Model Loss) 과 같이 난해도를 낮추기 위해 명시적으로 최적화하여 이를 직접 우회할 수 있다. 하지만 이 경우 공격 성공률이 낮아질 수 있다는 단점이 있다.
Jain et al. 2023 도 텍스트 입력을 사전 처리하여 의미론적 의미는 남긴 채 악의적인 수정을 제거하는 방법을 테스트했다.
Paraphrase: LLM을 사용하여 입력 텍스트를 의역하면 다운스트림 작업 성능에 약간의 영향을 미칠 수 있다.
Retokenization: 토큰을 분리하여 여러 개의 작은 토큰으로 표현하는 것으로, 예를 들어 BPE 드롭아웃(무작위 p% 토큰 드롭)을 통해 토큰을 분리한다. 공격자는 특정 토큰 조합을 악용할 가능성이 높다는 가설이 있다. 이는 공격 성공률을 낮추는 데 도움이 되지만 제한적이다(예: 90% 이상에서 40%로 감소).

굉장히 긴 내용이어서 자세히 다 읽지는 못했다.
다시 시간 내어서 꼼꼼히 읽어보아야겠다. Metrics 보면서 화이트박스 블랙박스 공격 메커니즘을 이해하는 시간을 깊게 가져야겠다.
이미지가 아닌 텍스트에서 LLM에 대한 적대적 공격 연구들이 이렇게 많다는 게 굉장히 흥미로웠다..
'인공지능 AI > 자연어처리' 카테고리의 다른 글
| [NLP/LLM] LLM 용어 정리 (0) | 2024.01.22 |
|---|---|
| [NLP/RE] RCL: Relation Contrastive Learning for Zero-Shot Relation Extraction (0) | 2023.03.09 |
| [NLP/RSNs/RE] Neural Snowball for Few-Shot Relation Learning (2) | 2023.02.22 |
| [논문리뷰/NLP/IR/NLG] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (0) | 2023.02.03 |
| [논문리뷰/NLP/IR] Dense passage retrieval for Open-Domain QA (1) | 2023.02.02 |